Preliminary Remarks on the Analytical Approach
Before moving through the individual findings, it is worth briefly orienting the reader to what this section does and does not claim. The analyses presented here draw on the CICIDS2017 dataset using the preprocessing pipeline and model configurations described in the Methodology. The visualizations — attack distribution, flow duration, packet size, destination port frequency, feature correlations, flow rate distribution, and classification performance — are presented in sequence, each building on the interpretive context established by the previous. The goal is not simply to report numbers but to construct a coherent account of what the data reveals about network traffic behavior, what that behavior implies for machine learning-based threat detection, and where — and why — the models perform as they do. Taken together, these results bear on the broader question of whether the proposed framework constitutes a meaningful contribution to intelligent governance in critical infrastructure cybersecurity (Patel & Patel, 2023).
4.1 Attack Label Distribution: Understanding the Composition of the Dataset
The first analytical step was to examine the distribution of traffic classes in the working dataset segment. [Figure 1] displays this distribution as a bar chart, comparing the volume of DDoS attack traffic against benign network traffic across the selected subset of CICIDS2017 records.
The imbalance is immediately apparent. DDoS traffic accounts for the larger share of records in this segment — a pattern that reflects, at least in part, the volume-intensive nature of denial-of-service attacks themselves. DDoS campaigns are, by design, characterized by massive packet floods, and this characteristic means that any captured traffic window during an active DDoS event will be numerically dominated by attack flows. Benign traffic, representing the normal operational baseline, occupies a smaller proportion in this subset (Okolo et al., 2023).
This distribution has real implications for how machine learning models are trained and evaluated. A classifier optimized on this imbalanced distribution could, in principle, achieve high accuracy simply by predicting the majority class for most inputs — a phenomenon known as the accuracy paradox, and one that makes class-specific metrics like recall and F1-score considerably more informative than raw accuracy alone. It also underscores the importance of stratified sampling during train-test splitting, which was applied throughout this study. That said, the dominance of DDoS traffic in this segment is not purely a statistical nuisance — it is an operationally meaningful signal. DDoS attacks remain among the most persistently deployed weapons against critical infrastructure networks, and a framework that fails to detect them reliably fails at one of its most basic requirements (Patriarca et al., 2022).
4.2 Flow Duration Distribution: What Timing Patterns Reveal About Traffic Behavior
[Figure 2] presents a histogram of network flow duration values across all records in the working dataset. The
Table 1. Metrics used in four classifiers on the held-out test set
|
Metric
|
Formula
|
Relevance in This Context
|
|
Accuracy
|
(TP + TN) / (TP + TN + FP + FN)
|
Overall classification correctness
|
|
Precision
|
TP / (TP + FP)
|
Proportion of flagged events that are genuine attacks
|
|
Recall (Sensitivity)
|
TP / (TP + FN)
|
Proportion of actual attacks successfully detected
|
|
F1-Score
|
2 × (Precision × Recall) / (Precision + Recall)
|
Harmonic balance between Precision and Recall
|
|
ROC-AUC
|
Area under the Receiver Operating Characteristic curve
|
Discrimination ability across all classification thresholds
|
|
False Positive Rate
|
FP / (FP + TN)
|
Rate of benign traffic misclassified as attacks
|
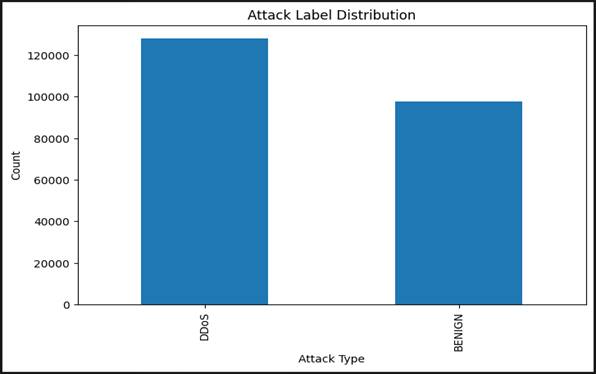
Figure 1. Class distribution of network traffic records in the CICIDS2017 working dataset: DDoS attack traffic versus benign traffic. Bar chart comparing absolute record counts for the two traffic classes used in binary classification experiments. The pronounced imbalance toward DDoS records reflects the volumetric character of denial-of-service campaigns, in which a single attack event generates disproportionately large numbers of network flows relative to normal user activity. This distribution informed the use of stratified sampling during train–test splitting and the selection of class-specific evaluation metrics (precision, recall, F1-score) alongside overall accuracy.
distribution is heavily right-skewed: the overwhelming majority of flows have very short durations, clustering near zero on the time axis, while a sparse but meaningful tail extends toward longer-duration flows.
This is, to some extent, expected. Most benign network communications — a DNS lookup, a brief HTTP exchange, a background telemetry packet — are resolved in milliseconds or a few seconds at most. Short flows dominate normal network behavior simply because most routine communications are transactional rather than sustained. What is more analytically interesting is the tail. Long-duration flows — those extending well beyond the typical communication window — are disproportionately associated with two behavioral categories: legitimate but persistent sessions (VPN tunnels, file transfers, streaming) and, more concerningly, certain classes of cyberattack that rely on sustained connection maintenance. Distributed Denial of Service attacks that employ TCP connection exhaustion strategies, for instance, deliberately maintain open connections to drain server resources; these would manifest as long-duration flows in this distribution (Chowdhury & Biswas, 2022).
For machine learning-based threat detection, flow duration is therefore a genuinely informative feature — not because any single duration threshold separates benign from malicious traffic cleanly, but because its combination with other features (packet rate, byte count, flag patterns) produces a discriminative signal that individual features cannot. This is exactly the kind of nuance that ensemble models like XGBoost and Random Forest are well positioned to exploit (Mehmood et al., 2023).
4.3 Average Packet Size by Traffic Class: A Behavioral Signature of DDoS Activity
[Figure 3] compares the average packet size — measured in bytes — between benign network traffic and DDoS attack traffic. The difference is striking and, from a network behavior standpoint, entirely consistent with what is understood about DDoS attack mechanics.
DDoS traffic exhibits substantially larger average packet sizes than benign traffic. This reflects the fundamental strategy of volumetric DDoS campaigns: flooding a target with maximum-size packets to saturate bandwidth and overwhelm processing capacity as rapidly as possible. Benign communications, by contrast, tend toward smaller, more varied packet sizes that reflect the heterogeneous nature of normal user activity — HTTP headers, acknowledgment packets, DNS queries, and brief API calls all contribute short, variable-length flows (Stanković et al., 2022).
The practical significance for intrusion detection is clear. Packet size, as a feature, carries genuine discriminative weight for DDoS classification — and this is not merely a finding of this study but is consistent with broader empirical work on network traffic characterization. What is worth noting, however, is that packet size alone is not a reliable classifier. Legitimate large-file transfers and video streaming traffic can also generate large average packet sizes. The value of this feature lies in its interaction with others — particularly flow rate, flag patterns, and destination port — within the multi-feature input space that the machine learning models operate on (Garcia-Perez et al., 2023).
4.4 Top Destination Port Analysis: Mapping Attack Surfaces to Network Services
[Figure 4] shows the frequency distribution of the top ten destination ports observed across all traffic records in the CICIDS2017 working dataset. Three ports account for the dominant share of traffic: port 80 (HTTP), port 443 (HTTPS), and port 53 (DNS).
This is not surprising — these are among the most heavily trafficked ports in any contemporary network environment, and their prevalence in the dataset simply reflects their centrality to normal web communication. Port 80 carries unencrypted web traffic; port 443 handles secure HTTPS sessions; port 53 manages domain name resolution requests. Any network, whether benign or adversarially probed, will show high volumes on these ports because they are the ports through which virtually all user-facing internet activity flows (Michalec et al., 2022).
What is analytically significant is not the presence of traffic on these ports, but rather the character of that traffic. Anomalous volumes, unusual packet structures, or unexpected timing patterns directed at ports 80, 443, and 53 are classic indicators of attack activity — DDoS flood traffic targeting web servers via HTTP/S, DNS amplification attacks exploiting port 53, and scanning activity probing open service ports. The destination port distribution therefore provides an important contextual layer for machine learning classification: models that incorporate port-level features alongside flow statistics can distinguish abnormal high-volume port activity from legitimate service traffic in ways that single-feature
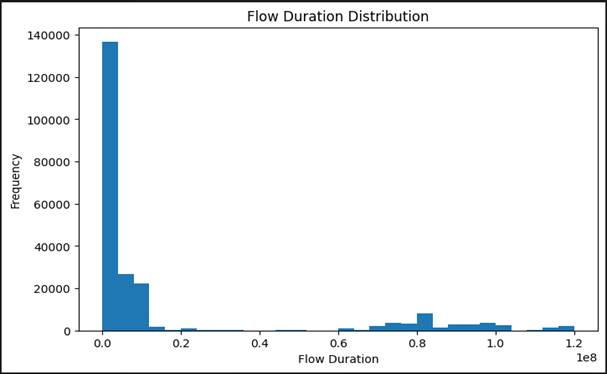
Figure 2. Distribution of network flow duration values across all traffic records in the CICIDS2017 working dataset. Right-skewed histogram showing the frequency of flow durations in microseconds. The majority of flows are concentrated at very short durations consistent with transactional benign communications (DNS lookups, brief HTTP exchanges). The sparse but analytically significant tail toward longer durations represents sustained connection flows associated with persistent sessions and certain attack behaviors, including TCP connection-exhaustion DDoS variants. Flow duration was retained in the final feature set on the basis of its discriminative contribution in conjunction with packet-rate and flag-pattern features.
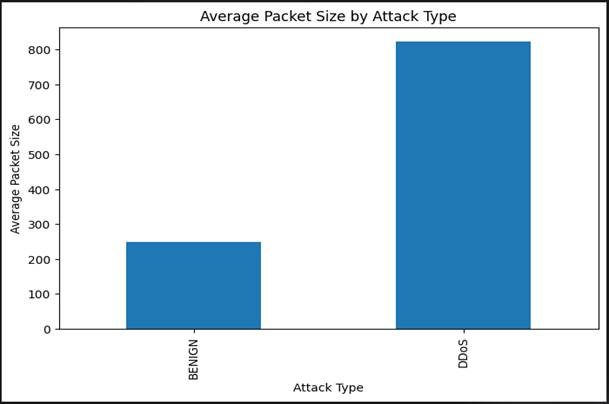
Figure 3. Mean packet size (bytes) compared between benign network traffic and DDoS attack traffic in the CICIDS2017 dataset. DDoS attack flows exhibit substantially larger mean packet sizes than benign flows, reflecting the maximum-size packet strategy common to volumetric denial-of-service campaigns designed to saturate target bandwidth. Benign traffic produces smaller, more heterogeneous packet sizes consistent with mixed-use communication patterns. This feature-level separation supports packet size as a discriminative classifier input, most reliably interpreted in combination with flow-rate and temporal features.
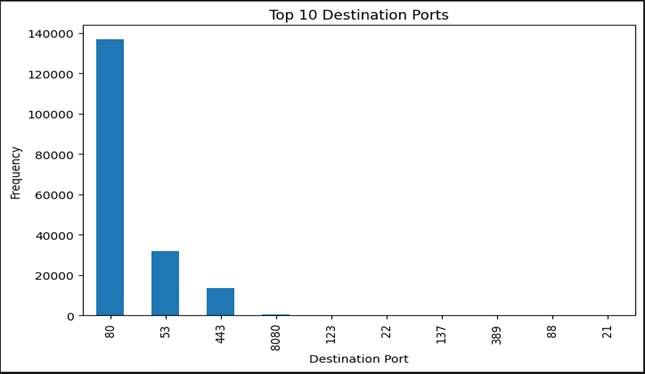
Figure 4. Frequency distribution of the ten most common destination ports observed across all network flow records in the CICIDS2017 working dataset. Port 80 (HTTP), port 443 (HTTPS), and port 53 (DNS) account for the largest traffic volumes, consistent with their role as primary conduits for web communication and domain resolution. Anomalous volumes directed at these ports — particularly in combination with unusual packet structures or flow-rate patterns — are characteristic indicators of DDoS flood attacks targeting web services, DNS amplification attacks, and application-layer intrusion attempts. Destination port was included as a categorical feature after label encoding.
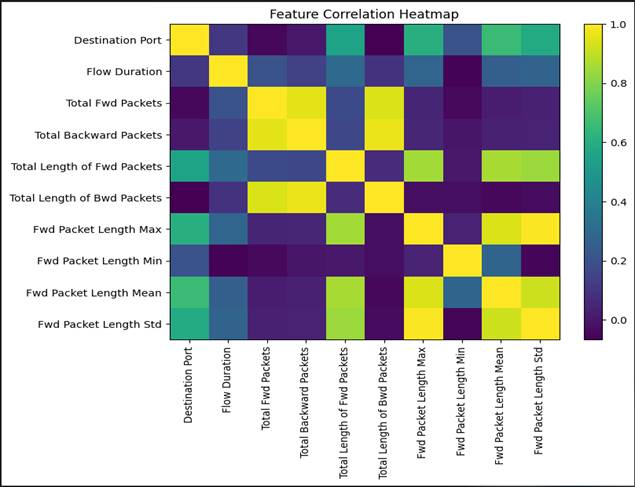
Figure 5. Pearson correlation heatmap of selected network traffic features from the CICIDS2017 dataset, illustrating inter-feature dependency structure used to guide feature selection. Cell color intensity scales with the magnitude of the Pearson correlation coefficient (r); darker cells indicate stronger linear relationships. Packet-volume features (Total Forward Packets, Total Backward Packets, Total Length of Forward Packets, Forward Packet Length Mean) form a strongly intercorrelated cluster (|r| approaching 1.0). Feature pairs with |r| > 0.95 were removed during preprocessing. Weakly correlated features — flag count statistics and inter-arrival timing variables — were retained for their orthogonal discriminative contribution. Abbreviations: FWD, forward; BWD, backward; PKT, packet; LEN, length; IAT, inter-arrival time.
analyses cannot (Ashfaq & Chowdhury, 2023).
4.5 Feature Correlation Analysis: Identifying Redundancy and Informative Structure
[Figure 5] presents a heatmap of Pearson correlation coefficients computed across the selected feature set from CICIDS2017. The color gradient encodes correlation strength, with darker shading indicating stronger relationships (positive or negative) between feature pairs.
Several clusters of high intercorrelation are immediately visible. Packet-volume features — Total Forward Packets, Total Backward Packets, Total Length of Forward Packets, and Forward Packet Length Mean — exhibit strong positive correlations with each other, which makes intuitive sense: networks that transmit many packets in a given flow tend to transmit larger total data volumes, and these quantities naturally covary. Similarly, inter-arrival time statistics (mean, standard deviation, minimum) form a loosely correlated cluster, reflecting the temporal regularity — or irregularity — of packet transmission patterns (Zubair et al., 2023).
As shown in [Table 1], feature pairs with absolute correlation coefficients above 0.95 were identified as candidates for removal during the feature selection stage, on the grounds that highly collinear features contribute redundant information without improving — and potentially degrading — classifier performance through multicollinearity. This procedure produced a reduced feature set that retains the most discriminative traffic characteristics while eliminating statistical duplication. Features with weaker or near-zero correlations (flag counts, certain timing statistics) provide orthogonal information that the packet-volume cluster does not capture, and their retention in the final feature set was confirmed through the feature importance ranking step described in the Methodology. The correlation analysis is, in this sense, not merely a data cleaning step — it is a form of structured exploratory analysis that reveals the underlying covariance geometry of the traffic data, and that geometry has direct implications for how machine learning models represent and distinguish traffic classes (Khan et al., 2022).
4.6 Flow Bytes per Second Distribution: Identifying High-Intensity Traffic Anomalies
[Figure 6] shows the distribution of Flow Bytes per Second (Flow Bytes/s) values across the working dataset. The histogram is steeply concentrated at the lower end of the scale, with the vast majority of flows transmitting at relatively modest data rates. A small but clearly visible tail extends toward extremely high flow byte rates.
The shape of this distribution carries genuine diagnostic value. Under normal operating conditions — routine web browsing, email exchange, API calls, background software updates — network flows operate at moderate throughputs that produce the dense low-rate cluster visible on the left side of the histogram. The sparse high-rate tail, by contrast, is where unusual traffic concentrates: large file transfers, streaming sessions, and, more relevantly for this study, the bandwidth-flooding characteristics of volumetric DDoS attacks. A single DDoS flow generating thousands of packets per second will produce a Flow Bytes/s value far to the right of the distribution median (Ampratwum et al., 2022).
This distributional characteristic makes Flow Bytes/s a valuable feature for machine learning-based anomaly detection, though — like all individual features — it must be interpreted in combination with others. A legitimate content delivery network (CDN) edge server could produce similarly elevated flow byte rates under heavy but entirely benign load conditions. The machine learning models in this study operate on the joint distribution of all retained features simultaneously, which is precisely why multi-feature ensemble approaches tend to outperform single-threshold detection rules on datasets with this kind of distributional complexity (Uzzaman & Rony, 2023).
4.7 SVM Classification Performance: Confusion Matrix Analysis
[Figure 7] presents the confusion matrix for the Support Vector Machine (SVM) classifier evaluated on the held-out test set from the CICIDS2017 working dataset. The matrix displays the four classification outcomes — true positives, true negatives, false positives, and false negatives — as cell counts, allowing a direct reading of where the model succeeds and where it errs.
The SVM correctly classified 1,918 benign traffic instances (true negatives) and 2,571 DDoS attack instances (true positives). Misclassifications were limited to seven benign records incorrectly labeled as DDoS (false positives) and four DDoS records incorrectly labeled as benign (false negatives). These are, by any reasonable standard, low error counts relative to the total test set size. The false positive rate — the proportion of benign traffic flagged as
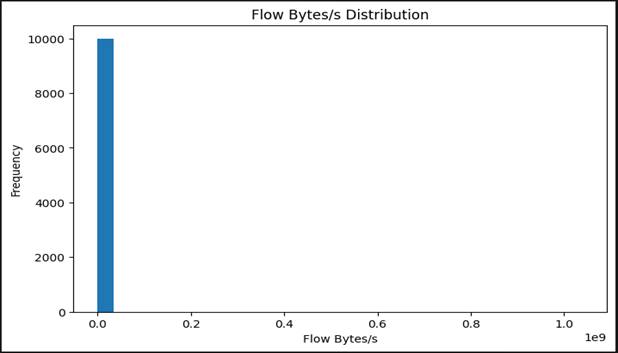
Figure 6. Frequency distribution of Flow Bytes per Second (Flow Bytes/s) values across all network flow records in the CICIDS2017 working dataset. The strongly right-skewed histogram shows the bulk of traffic at low-to-moderate throughput rates consistent with routine communications, with a sparse high-rate tail corresponding to bandwidth-intensive flows including volumetric DDoS attack traffic. Flow Bytes/s ranked among the highest-importance features in the XGBoost and Random Forest feature importance analyses. Abbreviation: Flow Bytes/s, total bytes transferred in a flow divided by flow duration in seconds.
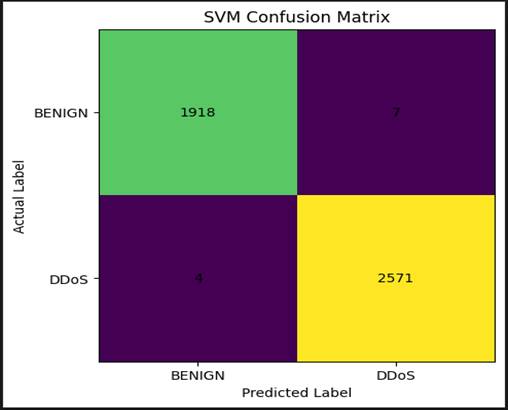
Figure 7. Confusion matrix for the Support Vector Machine (SVM) classifier evaluated on the held-out test set from the CICIDS2017 working dataset (binary classification: DDoS attack versus benign traffic). The SVM correctly identified 2,571 DDoS flows (true positives) and 1,918 benign flows (true negatives). Misclassifications comprised seven benign flows incorrectly labeled as DDoS (false positives) and four DDoS flows incorrectly labeled as benign (false negatives). The low false positive count reduces alert fatigue risk in operational deployments; the four false negatives, though small in absolute terms, represent the more consequential error type in critical infrastructure contexts where missed detections carry greater operational risk than false alarms. Abbreviations: SVM, Support Vector Machine; TP, true positive; TN, true negative; FP, false positive; FN, false negative.
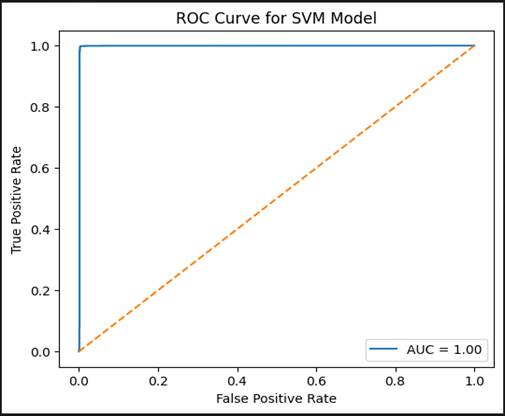
Figure 8. Receiver Operating Characteristic (ROC) curve for the SVM classifier on the binary DDoS versus benign traffic classification task. The y-axis plots the True Positive Rate (TPR; sensitivity) and the x-axis the False Positive Rate (FPR; 1 − specificity) across all classification decision thresholds. The diagonal dashed line represents chance-level discrimination (AUC = 0.50). The SVM curve tracks closely along the upper-left boundary, yielding an AUC approaching 1.00, indicating near-perfect discriminative ability across all threshold settings. Results are interpreted alongside Figure 7 and per-class precision, recall, and F1-score values, as AUC alone may be optimistic under class imbalance conditions. Abbreviations: ROC, Receiver Operating Characteristic; AUC, Area Under the Curve; TPR, True Positive Rate; FPR, False Positive Rate.
an attack — is particularly low, which matters operationally: excessive false alarms in a live critical infrastructure environment erode analyst trust and lead to alert fatigue, a well-documented failure mode in deployed security operations centers (Essien et al., 2022).
That said, the four false negatives — DDoS records that the SVM classified as benign — deserve more interpretive attention than the original framing would suggest. In a critical infrastructure context, a missed attack detection (false negative) carries asymmetrically greater consequences than a false alarm (false positive). A hospital network intrusion or energy grid DDoS campaign that evades detection, even briefly, can produce cascading harm that a false alarm never could. The SVM's performance here is genuinely strong, but these four misclassifications are worth tracking carefully as a potential failure mode under distribution shift — that is, when incoming traffic patterns diverge from those seen during training (Rezvani et al., 2023).
4.8 SVM ROC Curve Analysis: Discrimination Performance Across Classification Thresholds
[Figure 8] presents the Receiver Operating Characteristic (ROC) curve for the SVM classifier, plotting the True Positive Rate (TPR, or sensitivity) against the False Positive Rate (FPR) across the full range of classification decision thresholds. The diagonal dashed reference line represents the performance of a random classifier — one with no discriminative ability — and serves as a baseline against which the model curve is compared.
The SVM's ROC curve tracks tightly along the upper-left boundary of the plot, which is the region associated with high sensitivity and low false positive rates simultaneously. The Area Under the Curve (AUC) value approaches 1.00 — essentially near-perfect discrimination between DDoS attack traffic and benign traffic across all threshold settings. This is a strong result, and it is consistent with the confusion matrix findings: the model is not merely accurate at one particular operating point, but maintains that accuracy across a wide range of classification sensitivities (Alam & Fahad, 2022).
It is worth briefly noting what ROC-AUC does and does not tell us in a context like this. AUC close to 1.00 on a binary classification task with reasonably balanced classes — as is approximately the case here — is a meaningful indicator of model quality. However, AUC values computed on heavily imbalanced datasets can be misleadingly optimistic, because the denominator of the false positive rate is dominated by the large benign class. This is a reason why the confusion matrix, precision, recall, and F1-score are reported alongside AUC rather than as alternatives to it. The full picture of model reliability requires all of these lenses together, not any single one in isolation (Coppolino et al., 2023).
