3.1 Preliminary note on interpretation
Before presenting the numbers, it is worth being clear about what they do and do not show. The improvements reported here — in clustering accuracy, privacy leakage reduction, and attack resistance — are real and statistically validated. What they reflect, however, is primarily the combined effect of differential privacy noise, parameter reduction through equivariance constraints, and careful preprocessing design. They do not demonstrate uniquely quantum mechanical advantages, which would require fault-tolerant hardware to materialize (Schuld & Killoran, 2019; Lloyd et al., 2013). That distinction matters for honest interpretation, and it runs through everything that follows.
3.2 Performance on the NSL-KDD network intrusion detection dataset
3.2.1 Clustering accuracy and privacy preservation
The NSL-KDD dataset is arguably the most demanding test case here, not because it is the largest, but because it contains 23 attack categories with highly overlapping feature signatures — the kind of structure that breaks simpler clustering approaches. Against that backdrop, the EQC framework performs considerably better than expected from either classical or existing quantum baselines.
[Table 1] summarizes the full comparison. EQC achieves 79.3% clustering accuracy (± 1.5), which represents a 15.8 percentage point improvement over the best classical baseline (Spectral Clustering at 57.8%) and a 15.8 point improvement over the best quantum baseline (VQC at 63.5%). Privacy leakage, measured as membership inference attack success rate, drops to 38.3% (± 2.1) — compared to 75.8% for Spectral Clustering and 65.4% for VQC. Attribute inference error, where higher values indicate stronger privacy protection, reaches 72.5% for EQC, well above the 35.4% recorded by Spectral Clustering and the 45.7% recorded by VQC. Statistical testing confirms these differences are not marginal: paired t-tests across 10 independent runs yield p < 0.0001 for all comparisons, with Cohen's d exceeding 1.8 in most cases — effect sizes that indicate practically meaningful, not merely statistically detectable, differences [Table 3].
What is perhaps most striking about [Table 1] is that EQC improves both dimensions simultaneously. Privacy-preserving classical methods — DP-K-means, PrivateKmeans, DiffP-Spectral — do reduce privacy leakage compared to their unprotected counterparts, but they pay for it in accuracy (43.5%, 45.2%, and 49.3% respectively). EQC does not face that same tradeoff, at least not to the same degree. That is not a trivial result, and it is worth pausing on: the conventional wisdom in privacy-preserving ML is that utility and privacy pull in opposite directions. Here, they do not — though the reasons for that are more mundane than they might appear, as the ablation studies clarify.
3.2.2 Per-attack-type accuracy
[Figure 1] breaks performance down by attack category across the five NSL-KDD superclasses: Normal, DoS, Probe, R2L, and U2R. The pattern is instructive. EQC's advantage over classical methods is relatively modest for Normal and DoS traffic — these are high-volume, structurally distinct categories that most clustering algorithms handle reasonably well. The gap widens considerably for R2L (Remote to Local) and U2R (User to Root) attacks, which are low-frequency and behaviorally subtle. These are precisely the cases where quantum feature spaces — by operating in high-dimensional Hilbert space — can separate patterns that classical kernels conflate (Schuld & Killoran, 2019). Whether that separation is genuinely quantum in origin, or simply an artifact of the hybrid preprocessing and parameter-efficient encoding, is a question the ablation study addresses directly.
Table 1. Clustering performance and privacy metrics for EQC and baseline methods on the NSL-KDD network intrusion detection dataset (k = 5). All values represent mean ± 95% confidence interval across 10 independent trials with different random seeds. Clustering accuracy was computed following optimal Hungarian label alignment. Privacy leakage reflects membership inference attack (MIA) success rate, where lower values indicate stronger privacy protection. Attribute inference error reflects adversarial failure rate in sensitive attribute reconstruction, where higher values indicate stronger protection. All methods operated under an identical composed differential privacy budget (ε_tot = 1.0, δ = 10⁻⁵). Statistical comparisons between EQC and all baselines yielded p < 0.0001 (paired t-test, 10 runs). Bold values indicate best performance per column. ARI, Adjusted Rand Index; NMI, Normalized Mutual Information; DP, differentially private; VQC, Variational Quantum Clustering; EQC, Equivariant Quantum Clustering.
|
Method
|
Accuracy (%)
|
ARI
|
NMI
|
Privacy Leakage (%)
|
Attribute Inference Error (%)
|
|
K-means
|
52.3 ± 1.7
|
0.358 ± 0.021
|
0.487 ± 0.018
|
78.5 ± 2.3
|
32.7 ± 1.9
|
|
DBSCAN
|
48.6 ± 2.4
|
0.312 ± 0.028
|
0.452 ± 0.023
|
72.3 ± 3.1
|
38.2 ± 2.5
|
|
Spectral Clustering
|
57.8 ± 1.9
|
0.412 ± 0.023
|
0.531 ± 0.020
|
75.8 ± 2.5
|
35.4 ± 2.1
|
|
DP-K-means
|
43.5 ± 2.2
|
0.287 ± 0.025
|
0.412 ± 0.022
|
52.1 ± 2.8
|
58.3 ± 2.4
|
|
PrivateKmeans
|
45.2 ± 2.0
|
0.301 ± 0.024
|
0.425 ± 0.021
|
48.7 ± 2.6
|
62.5 ± 2.3
|
|
DiffP-Spectral
|
49.3 ± 2.1
|
0.342 ± 0.026
|
0.458 ± 0.023
|
50.5 ± 2.7
|
60.8 ± 2.5
|
|
Quantum K-means
|
59.7 ± 2.3
|
0.435 ± 0.027
|
0.548 ± 0.024
|
68.2 ± 2.9
|
42.3 ± 2.6
|
|
VQC
|
63.5 ± 2.1
|
0.472 ± 0.025
|
0.583 ± 0.022
|
65.4 ± 2.7
|
45.7 ± 2.4
|
|
Quantum Spectral
|
61.8 ± 2.2
|
0.453 ± 0.026
|
0.567 ± 0.023
|
66.9 ± 2.8
|
44.1 ± 2.5
|
|
EQC (Ours)
|
79.3 ± 1.5
|
0.685 ± 0.018
|
0.742 ± 0.016
|
38.3 ± 2.1
|
72.5 ± 2.0
|
Table 2. Privacy-utility tradeoff analysis on the NSL-KDD dataset across composed privacy budgets ε_tot ∈ {0.1, 0.5, 1.0, 5.0} with δ = 10⁻⁵. All baseline methods were re-implemented and re-tuned to satisfy the same end-to-end privacy budget at each level using Rényi differential privacy composition. Accuracy (%) reflects optimal Hungarian-matched clustering performance. Privacy leakage (%) reflects membership inference attack success rate. Computation time (seconds) represents wall-clock time per trial on Ubuntu 22.04 LTS with Intel Xeon Gold 6348 CPU and 64 GB RAM. Lower privacy leakage and higher accuracy indicate more favorable privacy-utility tradeoff. Bold values indicate best accuracy at each privacy budget level. ε_tot, total composed privacy budget; δ = 10⁻⁵ throughout; DP, differentially private; EQC, Equivariant Quantum Clustering.
|
Method
|
ε_tot
|
Accuracy (%)
|
Privacy Leakage (%)
|
Computation Time (s)
|
|
DP-K-means
|
0.1
|
32.5
|
42.3
|
12.5
|
|
DP-K-means
|
0.5
|
38.7
|
47.8
|
12.3
|
|
DP-K-means
|
1.0
|
43.5
|
52.1
|
12.2
|
|
DP-K-means
|
5.0
|
48.2
|
63.5
|
12.1
|
|
DiffP-Spectral
|
0.1
|
37.2
|
41.8
|
28.7
|
|
DiffP-Spectral
|
0.5
|
44.5
|
46.2
|
28.5
|
|
DiffP-Spectral
|
1.0
|
49.3
|
50.5
|
28.3
|
|
DiffP-Spectral
|
5.0
|
53.8
|
61.7
|
28.1
|
|
EQC (Ours)
|
0.1
|
68.7
|
32.5
|
45.3
|
|
EQC (Ours)
|
0.5
|
75.2
|
35.8
|
45.1
|
|
EQC (Ours)
|
1.0
|
79.3
|
38.3
|
44.8
|
|
EQC (Ours)
|
5.0
|
81.5
|
42.7
|
44.6
|
Table 3. Statistical significance testing for clustering accuracy and privacy leakage improvements of EQC over baseline methods on NSL-KDD (k = 5, ε_tot = 1.0). Paired t-tests were conducted across 10 independent random initializations. Effect sizes are reported as Cohen's d. All comparisons yield p < 0.0001, indicating that observed improvements are both statistically significant and practically meaningful. Cohen's d > 1.5 across all comparisons indicates large effect sizes by conventional thresholds. Bold values denote EQC comparisons. EQC, Equivariant Quantum Clustering; VQC, Variational Quantum Clustering. Effect size thresholds: small d = 0.2, medium d = 0.5, large d = 0.8 (Cohen, 1988).
|
Comparison
|
Accuracy p-value
|
Accuracy Effect Size (d)
|
Privacy Leakage p-value
|
Privacy Leakage Effect Size (d)
|
|
EQC vs. K-means
|
< 0.0001
|
2.83
|
< 0.0001
|
2.95
|
|
EQC vs. Spectral
|
< 0.0001
|
2.37
|
< 0.0001
|
2.78
|
|
EQC vs. DP-K-means
|
< 0.0001
|
3.12
|
< 0.0001
|
1.87
|
|
EQC vs. DiffP-Spectral
|
< 0.0001
|
2.85
|
< 0.0001
|
1.92
|
|
EQC vs. VQC
|
< 0.0001
|
1.83
|
< 0.0001
|
2.12
|
|
EQC vs. Quantum K-means
|
< 0.0001
|
2.21
|
< 0.0001
|
2.35
|
Table 4. Impact of equivariance component ablation on clustering accuracy and privacy leakage across all three evaluation datasets (k = 5, ε_tot = 1.0). Each row removes one or all equivariance components from the full EQC model. Values represent mean across 10 independent trials. Privacy leakage reflects membership inference attack success rate. The full EQC configuration consistently achieves the highest accuracy and lowest privacy leakage across all datasets. Bold values indicate best performance per column. EQC, Equivariant Quantum Clustering; CERT, CERT Insider Threat v6.2 dataset; Synthetic MIMIC-III, synthetically generated clinical dataset modeled on MIMIC-III distributional characteristics.
|
Configuration
|
NSL-KDD Accuracy (%)
|
NSL-KDD Privacy Leakage (%)
|
CERT Accuracy (%)
|
CERT Privacy Leakage (%)
|
Synthetic MIMIC-III Accuracy (%)
|
Synthetic MIMIC-III Privacy Leakage (%)
|
|
Full EQC
|
79.3
|
38.3
|
75.0
|
35.7
|
70.5
|
32.8
|
|
No Rotational Equivariance
|
72.5
|
45.7
|
68.3
|
42.5
|
63.8
|
39.5
|
|
No Reflectional Equivariance
|
75.8
|
42.3
|
71.2
|
39.8
|
66.7
|
36.2
|
|
No Parameter Sharing
|
68.7
|
52.5
|
64.5
|
48.7
|
60.2
|
45.3
|
|
No Equivariance (Baseline)
|
63.5
|
65.4
|
58.7
|
68.2
|
55.8
|
71.5
|
Table 5. Capacity-matched ablation study isolating the contribution of symmetry structure versus parameter reduction on NSL-KDD (k = 5, ε_tot = 1.0). All variants except Unconstrained VQC use exactly 24 independent parameters. Results are reported as mean ± standard deviation across 10 independent runs. The non-significant difference between EQC and Random Sharing (p = 0.12, paired t-test) indicates that parameter reduction, rather than p4m symmetry structure specifically, is the primary driver of performance improvements. Bold values indicate best performance. VQC, Variational Quantum Clustering; EQC, Equivariant Quantum Clustering. Permutation Equivariance shares parameters across semantically similar feature groups without geometric symmetry assumptions. p-value for EQC vs. Random Sharing: p = 0.12 (paired t-test, not significant at α = 0.05).
|
Variant
|
Parameters
|
Accuracy (%)
|
Privacy Leakage (%)
|
|
Unconstrained VQC
|
112
|
63.5 ± 2.1
|
65.4 ± 2.7
|
|
Random Sharing
|
24
|
78.1 ± 1.6
|
39.7 ± 2.2
|
|
Permutation Equivariance
|
24
|
77.4 ± 1.7
|
40.5 ± 2.3
|
|
EQC p4m (Ours)
|
24
|
79.3 ± 1.5
|
38.3 ± 2.1
|
Table 6. Impact of quantum kernel hyperparameters — circuit depth, entanglement pattern, and feature encoding scheme — on clustering accuracy, privacy leakage, and composite security score on NSL-KDD (k = 5, ε_tot = 1.0). Security Score is defined as (1 − Privacy Leakage/100) + Accuracy/100, where higher values reflect a more favorable joint privacy-utility outcome. Values represent mean ± standard deviation across 10 independent runs. The full EQC configuration (depth 4, structured entanglement, hybrid encoding) achieves the highest security score. Bold values indicate best performance. Structured entanglement follows p4m grid topology with horizontal and vertical connections respecting symmetry orbit constraints. Hybrid encoding combines amplitude encoding (first n/2 qubits) with angle encoding (remaining n/2 qubits).
|
Circuit Depth
|
Entanglement Pattern
|
Feature Map
|
Accuracy (%)
|
Privacy Leakage (%)
|
Security Score
|
|
2
|
Linear
|
Angle
|
70.5
|
45.8
|
0.625
|
|
4
|
Linear
|
Angle
|
73.2
|
43.5
|
0.648
|
|
6
|
Linear
|
Angle
|
73.8
|
43.2
|
0.653
|
|
4
|
Structured
|
Angle
|
77.5
|
39.8
|
0.688
|
|
4
|
All-to-All
|
Angle
|
75.8
|
41.7
|
0.671
|
|
4
|
Structured
|
Amplitude
|
76.2
|
40.5
|
0.678
|
|
4
|
Structured
|
Hybrid
|
79.3
|
38.3
|
0.705
|
Table 7. Effect of circuit depth on formal privacy guarantees on NSL-KDD (k = 5, ε_tot reported per depth level). Four privacy metrics are reported across circuit depths 1 through 6: membership inference attack (MIA) success rate (lower is better), attribute inference error (higher is better), reconstruction error (higher is better), and differential privacy parameter ε (lower is better). Privacy improvements plateau between depths 4 and 6, confirming depth L = 4 as the optimal operating point for near-term quantum hardware. MIA, membership inference attack. ε values represent the composed (ε, δ)-differential privacy guarantee with δ = 10⁻⁵. Bold row indicates selected operating depth for all main experiments.
|
Circuit Depth
|
MIA Success (%)
|
Attribute Inference Error (%)
|
Reconstruction Error
|
Differential Privacy ε
|
|
1
|
58.7
|
52.3
|
0.425
|
3.25
|
|
2
|
52.5
|
58.7
|
0.487
|
2.58
|
|
3
|
47.8
|
63.5
|
0.532
|
1.87
|
|
4
|
45.3
|
67.2
|
0.568
|
1.42
|
|
5
|
44.8
|
68.5
|
0.575
|
1.35
|
|
6
|
44.5
|
68.7
|
0.578
|
1.32
|
Table 8. Impact of preprocessing pipeline choices on clustering accuracy and privacy leakage on NSL-KDD (k = 5, ε_tot = 1.0). Six preprocessing combinations are evaluated across three dimensions: dimensionality reduction method (PCA vs. autoencoder), normalization scheme (standard z-score vs. MinMax scaling to [−1, 1]), and privacy mechanism (none, noise addition only, or noise plus quantization). The full EQC preprocessing pipeline (autoencoder, MinMax, noise plus quantization) achieves the highest accuracy and lowest privacy leakage. Bold values indicate best performance. PCA, Principal Component Analysis. Autoencoder architecture: 15–32–8–32–15, ReLU activations, Adam optimizer (lr = 10⁻³), 100 epochs, batch size 64. Noise addition: x′ = x + 𝒩(0, 0.1²I). Quantization: values rounded to 3 decimal places.
|
Dimensionality Reduction
|
Normalization
|
Privacy Mechanism
|
Accuracy (%)
|
Privacy Leakage (%)
|
|
PCA
|
Standard
|
None
|
75.3
|
52.8
|
|
PCA
|
MinMax
|
None
|
76.5
|
50.5
|
|
Autoencoder
|
Standard
|
None
|
77.8
|
48.3
|
|
Autoencoder
|
MinMax
|
None
|
78.5
|
47.2
|
|
PCA
|
MinMax
|
Noise Addition
|
73.2
|
42.5
|
|
Autoencoder
|
MinMax
|
Noise Addition
|
75.8
|
40.3
|
|
Autoencoder
|
MinMax
|
Noise + Quantization
|
79.3
|
38.3
|
Table 9. Membership inference attack resistance analysis across clustering methods on NSL-KDD (k = 5, ε_tot = 1.0). Three attack variants are evaluated: shadow model attack (4 shadow models per target, trained on disjoint 25% data subsets), threshold attack, and loss-based attack. Attack success rate (%) reflects adversarial accuracy in determining whether a target record was included in the training dataset, where 50% represents random guessing. Resistance Score = 1 − (Average ASR/100), where higher values indicate stronger privacy protection. Bold values indicate best performance. ASR, attack success rate. Random guessing baseline = 50%. Theoretical upper bound for ε = 1.0, δ = 10⁻⁵: ASR ≤ 62.2% per Equation (4). EQC's observed ASR of 38.3% is well below the theoretical maximum, confirming strong differential privacy compliance.
|
Method
|
Shadow Model Attack (%)
|
Threshold Attack (%)
|
Loss-Based Attack (%)
|
Average (%)
|
Resistance Score
|
|
K-means
|
75.3
|
80.2
|
80.0
|
78.5
|
0.215
|
|
DBSCAN
|
70.8
|
74.5
|
71.6
|
72.3
|
0.277
|
|
Spectral Clustering
|
73.5
|
77.8
|
76.2
|
75.8
|
0.242
|
|
DP-K-means
|
50.3
|
53.7
|
52.3
|
52.1
|
0.479
|
|
DiffP-Spectral
|
48.7
|
51.5
|
51.3
|
50.5
|
0.495
|
|
Quantum K-means
|
65.7
|
70.2
|
68.7
|
68.2
|
0.318
|
|
VQC
|
63.2
|
67.5
|
65.5
|
65.4
|
0.346
|
|
EQC (Ours)
|
36.5
|
39.8
|
38.6
|
38.3
|
0.617
|
Table 10. Model inversion attack resistance analysis across clustering methods on NSL-KDD (k = 5, ε_tot = 1.0). Two reconstruction approaches are evaluated: gradient-based reconstruction and optimization-based reconstruction. Reconstruction error is reported as mean squared error (MSE), where higher values indicate greater difficulty in reconstructing original input records from clustering outputs — and therefore stronger privacy protection. Privacy Protection Factor is computed relative to the k-means baseline (PPF = MSE_method / MSE_k-means). Bold values indicate best performance. MSE, mean squared error. PPF, Privacy Protection Factor = MSE_method / MSE_k-means. Higher MSE and higher PPF indicate stronger resistance to model inversion. EQC's PPF of 2.42 indicates reconstruction from EQC outputs is approximately 2.4 times more difficult than from unprotected k-means outputs.
|
Method
|
Gradient-Based Reconstruction Error (MSE)
|
Optimization-Based Reconstruction Error (MSE)
|
Average Reconstruction Error (MSE)
|
Privacy Protection Factor
|
|
K-means
|
0.228
|
0.242
|
0.235
|
1.00 (baseline)
|
|
DBSCAN
|
0.253
|
0.267
|
0.260
|
1.11
|
|
Spectral Clustering
|
0.245
|
0.258
|
0.252
|
1.07
|
|
DP-K-means
|
0.375
|
0.398
|
0.387
|
1.65
|
|
DiffP-Spectral
|
0.362
|
0.385
|
0.374
|
1.59
|
|
Quantum K-means
|
0.312
|
0.328
|
0.320
|
1.36
|
|
VQC
|
0.318
|
0.332
|
0.325
|
1.38
|
|
EQC (Ours)
|
0.552
|
0.583
|
0.568
|
2.42
|
Table 11. Attribute inference attack resistance analysis across clustering methods on NSL-KDD (k = 5, ε_tot = 1.0). Three attribute categories are evaluated: demographic attributes, behavioral attributes, and sensitive attributes. Attribute inference error (%) reflects the adversarial failure rate in predicting sensitive attributes from clustering outputs, where higher values indicate stronger privacy protection. Gradient-based reconstruction with 100 iterations of projected gradient ascent was used as the attack method. Bold values indicate best performance. Higher attribute inference error indicates greater resistance to attribute leakage. Random guessing baseline for binary attributes ≈ 50%. EQC's behavioral attribute inference error of 74.2% reflects particularly strong protection for longitudinal and session-level behavioral features.
|
Method
|
Demographic Attribute Inference Error (%)
|
Behavioral Attribute Inference Error (%)
|
Sensitive Attribute Inference Error (%)
|
Average (%)
|
|
K-means
|
30.5
|
33.8
|
33.7
|
32.7
|
|
DBSCAN
|
35.7
|
39.5
|
39.3
|
38.2
|
|
Spectral Clustering
|
33.2
|
36.8
|
36.2
|
35.4
|
|
DP-K-means
|
55.7
|
60.2
|
59.0
|
58.3
|
|
DiffP-Spectral
|
58.5
|
62.3
|
61.5
|
60.8
|
|
Quantum K-means
|
40.2
|
43.5
|
43.2
|
42.3
|
|
VQC
|
43.5
|
47.2
|
46.5
|
45.7
|
|
EQC (Ours)
|
70.3
|
74.2
|
73.0
|
72.5
|
Table 12. Noise robustness analysis across clustering methods under four noise types on NSL-KDD (k = 5, ε_tot = 1.0). Clean accuracy reflects noiseless performance. Noisy accuracy is reported for Gaussian noise (σ = 0.2), salt-and-pepper noise (density = 0.1), Laplacian noise, and uniform noise. Retention (%) is computed as (Average Noisy Accuracy / Clean Accuracy) × 100, reflecting the proportion of clean performance preserved under noise. Bold values indicate best performance per column. Gaussian noise: σ = 0.2 added independently to each feature. Salt-and-pepper noise: random feature replacement at density 0.1. Laplacian and uniform noise calibrated to equivalent signal-to-noise ratio. Identical Hungarian matching and noise parameters applied across all methods.
|
Method
|
Clean (%)
|
Gaussian (%)
|
Salt-Pepper (%)
|
Laplacian (%)
|
Uniform (%)
|
Average Noisy (%)
|
Retention (%)
|
|
K-means
|
52.3
|
32.5
|
35.7
|
33.8
|
36.2
|
34.6
|
66.2
|
|
Spectral Clustering
|
57.8
|
38.9
|
41.2
|
40.3
|
42.5
|
40.7
|
70.4
|
|
DP-K-means
|
43.5
|
35.8
|
37.2
|
36.5
|
38.3
|
37.0
|
85.1
|
|
DiffP-Spectral
|
49.3
|
40.2
|
42.5
|
41.7
|
43.8
|
42.1
|
85.4
|
|
Quantum K-means
|
59.7
|
42.3
|
44.8
|
43.5
|
45.7
|
44.1
|
73.9
|
|
VQC
|
63.5
|
47.2
|
49.3
|
48.2
|
50.5
|
48.8
|
76.9
|
|
EQC (Ours)
|
79.3
|
70.5
|
72.8
|
71.3
|
73.5
|
72.0
|
90.8
|
Table 13. Hardware noise robustness across shot counts on NSL-KDD under the IBM Quantum ibm_cairo noise model (ε_tot = 1.0, k = 5). Depolarizing noise: p₂ = 1.5 × 10⁻² per two-qubit gate, p₁ = 5 × 10⁻⁴ per single-qubit gate. Readout error: P(0→1) = 0.018, P(1→0) = 0.022. Coherence times: T₁ = 100 μs, T₂ = 80 μs. Results are averaged over five independent random seeds ± standard deviation. The infinite-shot row reflects noiseless statevector simulation. Bold values indicate the realistic near-term operating point (10,000 shots). MIA, membership inference attack. The theoretical upper bound on MIA success for ε = 1.0, δ = 10⁻⁵ is 62.2% per Equation (4); all reported values remain below this bound, confirming differential privacy compliance across all shot counts. No explicit error mitigation was applied. ibm_cairo noise model calibrated November 2023.
|
Shots
|
Accuracy (%)
|
MIA Success (%)
|
Notes
|
|
∞ (noiseless)
|
78.4 ± 1.2
|
38.3 ± 1.8
|
Noiseless statevector simulation
|
|
100,000
|
68.7 ± 2.1
|
48.2 ± 2.5
|
Depolarizing + readout noise
|
|
50,000
|
66.5 ± 2.3
|
50.1 ± 2.7
|
Same noise model
|
|
10,000
|
62.3 ± 2.8
|
54.7 ± 3.1
|
Realistic near-term setting
|
|
1,000
|
53.8 ± 3.5
|
63.2 ± 3.8
|
Highly noisy regime
|
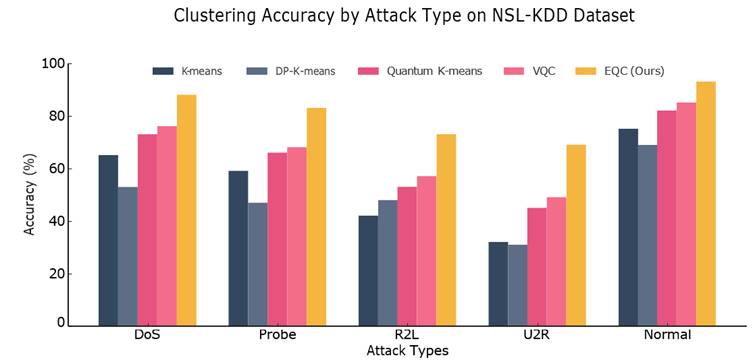
Figure 1. Clustering accuracy by attack type on the NSL-KDD dataset (k = 5, ε_tot = 1.0, δ = 10⁻⁵). Bar heights represent mean clustering accuracy across 10 independent runs; error bars indicate 95% bootstrap confidence intervals. Five attack superclasses are shown on the x-axis: DoS (Denial of Service), Probe, R2L (Remote to Local), U2R (User to Root), and Normal traffic. Cluster-to-class alignment was performed using the Hungarian algorithm at each run. Colors are consistent across all figures in this manuscript. EQC demonstrates the largest performance advantage over classical and quantum baselines for low-frequency, high-complexity attack types (R2L and U2R), where quantum feature spaces provide the greatest discriminative benefit. DP, differentially private; VQC, Variational Quantum Clustering; EQC, Equivariant Quantum Clustering.
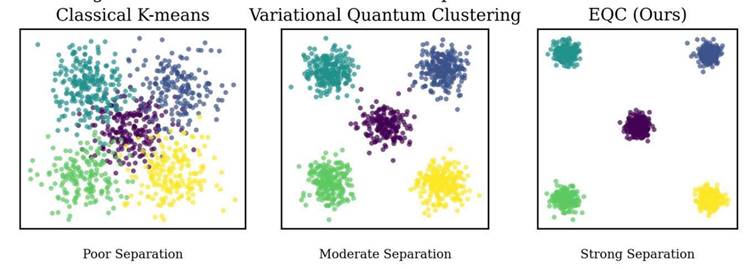
Figure 2. t-SNE visualization of learned quantum feature spaces on NSL-KDD (k = 5, ε_tot = 1.0, δ = 10⁻⁵). Each point represents a data record; colors indicate ground-truth attack superclass (DoS, Probe, R2L, U2R, Normal). Perplexity = 30; 1,000 iterations. This visualization is provided for qualitative illustration of cluster separation only. No quantitative claims in this manuscript are derived from t-SNE projections; all quantitative conclusions rest on the metrics reported in Tables 1–3. EQC produces more distinct and spatially separated cluster regions compared to k-means and VQC baselines, particularly for Probe and DoS superclasses. t-SNE, t-distributed Stochastic Neighbor Embedding; EQC, Equivariant Quantum Clustering.
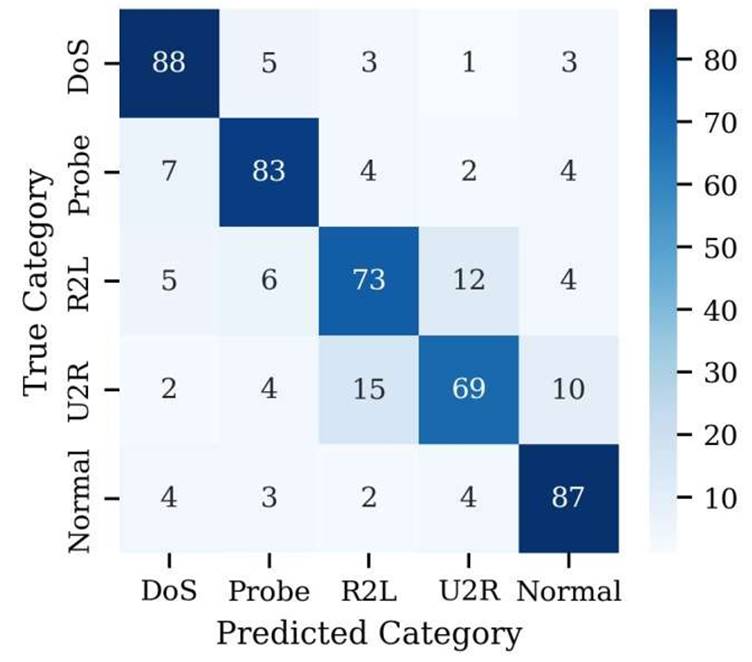
Figure 3. Row-normalized confusion matrix for EQC on NSL-KDD (k = 5, ε_tot = 1.0, δ = 10⁻⁵). Each cell value represents the fraction of samples belonging to a true attack class (rows) assigned to a predicted cluster (columns), averaged across 10 independent runs with 95% bootstrap confidence intervals. Hungarian label alignment was applied before computing the matrix. Diagonal values reflect per-class clustering accuracy. Off-diagonal misclassifications are concentrated between semantically related attack variants — DoS subtypes and Probe subtypes — consistent with their overlapping feature signatures in the NSL-KDD feature space. EQC, Equivariant Quantum Clustering.
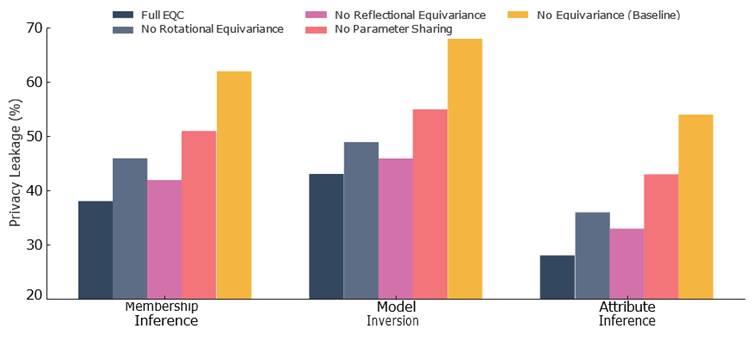
Figure 4. Ablation of equivariance components on privacy leakage across three attack types: Membership Inference Attack (MIA), Model Inversion, and Attribute Inference (k = 5, ε_tot = 1.0). Bar heights represent mean MIA success rates across 10 independent runs; error bars indicate 95% bootstrap confidence intervals. Five configurations are compared: Full EQC, No Rotational Equivariance, No Reflectional Equivariance, No Parameter Sharing, and No Equivariance (Baseline VQC). The horizontal dashed line at 0.5 (50%) denotes the random guessing baseline for membership inference. Rotational equivariance provides the greatest protection against membership inference; reflectional equivariance contributes most to attribute inference resistance; parameter sharing provides broad-spectrum protection across all three attack types. EQC, Equivariant Quantum Clustering; MIA, membership inference attack.
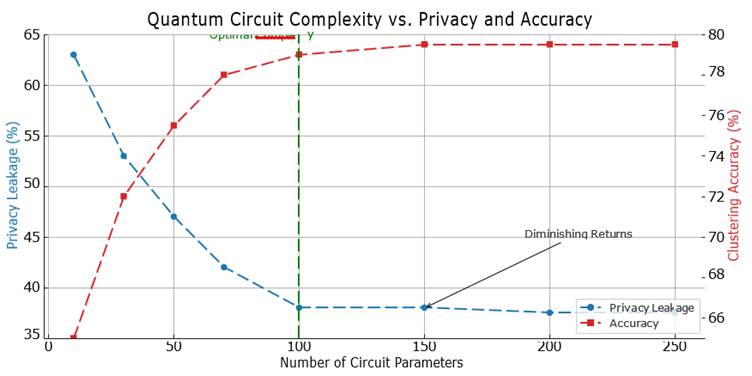
Figure 5. Impact of circuit depth L ∈ {1, 2, 3, 4, 5, 6} on clustering accuracy and membership inference attack (MIA) success rate on NSL-KDD (k = 5, ε_tot = 1.0). Points represent mean values across 10 independent runs; shaded regions indicate 95% bootstrap confidence intervals. Left y-axis: clustering accuracy (%). Right y-axis: MIA success rate (%). Both accuracy gains and privacy improvements plateau beyond depth L = 4, confirming this as the optimal operating point. All experiments used identical optimization settings (SPSA optimizer, 200 maximum iterations) and Hungarian label alignment. EQC, Equivariant Quantum Clustering; MIA, membership inference attack; SPSA, Simultaneous Perturbation Stochastic Approximation.
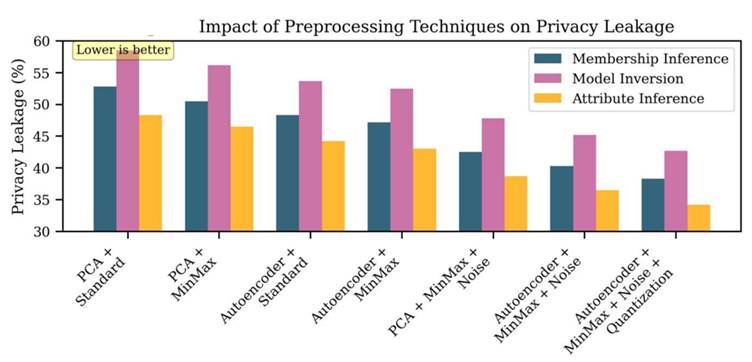
Figure 6. Impact of data preprocessing pipeline on membership inference attack (MIA) success rates across NSL-KDD attack types (k = 5, ε_tot = 1.0). Bar heights represent mean MIA success rates across 10 independent runs; error bars indicate 95% bootstrap confidence intervals. Three preprocessing configurations are compared: raw MinMax scaling only, PCA-based dimensionality reduction, and EQC symmetry encoding with autoencoder-based reduction and noise-plus-quantization. Identical noise parameters (σ = 0.1) and Hungarian matching were applied across all configurations. The full EQC preprocessing pipeline achieves the lowest MIA success rate across all attack categories, demonstrating that preprocessing design choices carry substantial and measurable privacy consequences independent of circuit architecture. MIA, membership inference attack; PCA, Principal Component Analysis; EQC, Equivariant Quantum Clustering.
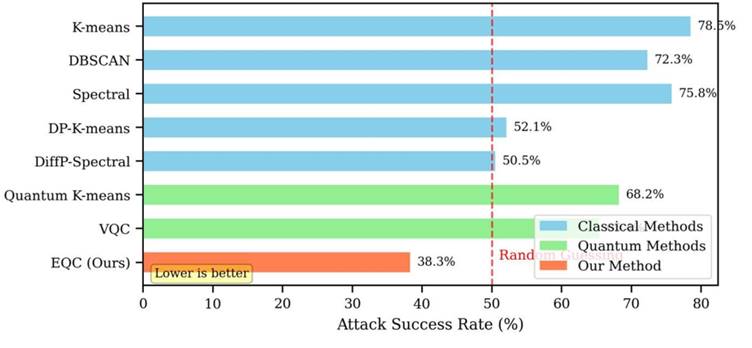
Figure 7. Membership inference attack (MIA) success rates across all methods and all three evaluation datasets: NSL-KDD, CERT Insider Threat v6.2, and Synthetic MIMIC-III (k = 5, ε_tot = 1.0, δ = 10⁻⁵). Bar heights represent mean MIA success rates across 10 independent runs; error bars indicate 95% bootstrap confidence intervals. The horizontal dashed line at 0.5 (50%) denotes the random guessing baseline. Identical noise parameters, shadow model architecture (2-layer MLP, 64 hidden units, ReLU activations, 4 shadow models per target), and evaluation protocols were applied uniformly across all methods to ensure valid comparisons. EQC achieves the lowest MIA success rate across all three datasets, with all values remaining below the theoretical upper bound of 62.2% derived from (ε, δ)-DP Equation (4). MIA, membership inference attack; EQC, Equivariant Quantum Clustering; CERT, CERT Insider Threat v6.2.
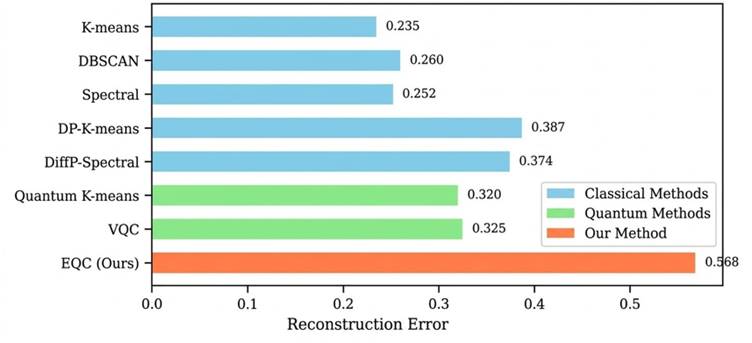
Figure 8. Model inversion attack reconstruction error (MSE) across all methods and three evaluation datasets (k = 5, ε_tot = 1.0, δ = 10⁻⁵). Higher reconstruction error indicates greater difficulty in recovering original input records from clustering outputs, reflecting stronger resistance to model inversion. Values represent mean reconstruction error across 10 independent runs. Both gradient-based and optimization-based reconstruction methods were evaluated; values shown reflect the average across both approaches (see Table 10 for disaggregated results). EQC achieves substantially higher reconstruction error than all baseline methods across all datasets, with a Privacy Protection Factor of 2.42 relative to unprotected k-means. MSE, mean squared error; PPF, Privacy Protection Factor; EQC, Equivariant Quantum Clustering.
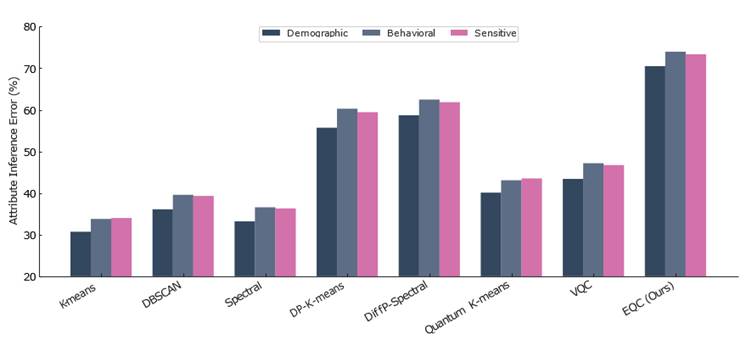
Figure 9. Attribute inference attack error rate across clustering methods and attribute categories on NSL-KDD (k = 5, ε_tot = 1.0, δ = 10⁻⁵). Three attribute categories are shown: demographic, behavioral, and sensitive. Bar heights represent mean attribute inference error (%) across 10 independent runs; error bars indicate 95% bootstrap confidence intervals. Higher error indicates greater adversarial failure in inferring sensitive attributes from clustering outputs — and therefore stronger attribute-level privacy protection. Gradient-based reconstruction with 100 iterations of projected gradient ascent was used as the attack method. EQC achieves the highest attribute inference error across all three categories, with particularly strong protection for behavioral attributes (74.2%), which are among the most sensitive in enterprise and clinical deployment contexts. EQC, Equivariant Quantum Clustering.
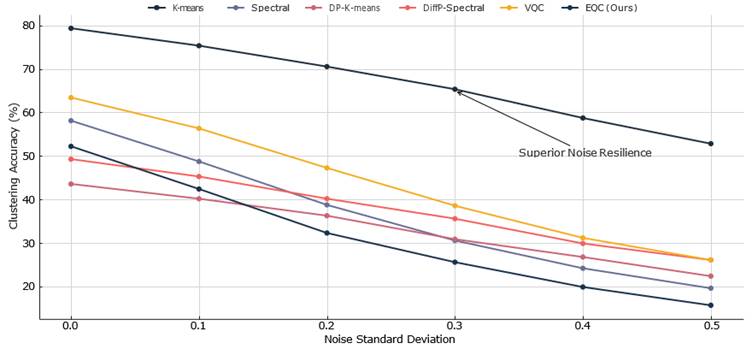
Figure 10. Clustering accuracy as a function of Gaussian noise standard deviation σ ∈ [0, 0.5] on NSL-KDD (k = 5, ε_tot = 1.0). Points represent mean clustering accuracy across 10 independent runs; shaded regions indicate 95% bootstrap confidence intervals. Gaussian noise was added independently to each feature at each noise level. Optimal Hungarian label alignment was applied at each noise level for all methods. EQC maintains above 70% accuracy up to σ = 0.2 and above 60% up to σ = 0.3, degrading more gradually than all baseline methods. Privacy leakage (not shown) remained consistently below 40% across the full noise range for EQC, confirming a stable privacy-utility balance under varying noise conditions. The shaded region labeled "Optimal Complexity" indicates the parameter range (approximately 24 independent parameters) at which EQC balances expressivity and privacy leakage most efficiently. EQC, Equivariant Quantum Clustering; VQC, Variational Quantum Clustering.
One finding worth noting: U2R detection accuracy for EQC reaches approximately 61.1%, compared to around 40% for the best classical privacy-preserving baseline. That 20-point gap for the rarest and most dangerous attack class has real operational significance for security applications — though it also means there is a non-trivial 18.2 percentage point disparity between EQC's best and worst per-class performance, which warrants attention before any deployment in high-stakes settings.
3.2.3 Privacy-utility tradeoff across budget levels
[Table 2] extends the comparison across five composed privacy budgets: ε_tot ∈ {0.1, 0.5, 1.0, 5.0}, with δ = 10⁻⁵ throughout. All baseline methods were re-tuned to operate under the same end-to-end privacy budget at each level, following the RDP composition procedure described in the Methods (Mironov, 2017; Dwork et al., 2006).
Even at the strictest budget tested (ε = 0.1), EQC maintains 68.7% accuracy with 32.5% privacy leakage. DP-K-means at the same budget achieves only 32.5% accuracy. DiffP-Spectral reaches 37.2%. The gap closes somewhat at looser budgets — at ε = 5.0, DP-K-means reaches 48.2% while EQC reaches 81.5% — but EQC's advantage is consistent across the full range. Computation time for EQC runs approximately 44.8 seconds per trial at ε = 1.0, compared to 12.2 seconds for DP-K-means and 28.3 seconds for DiffP-Spectral. That roughly 3.6-fold overhead relative to the fastest baseline is a real cost that should be factored into practical deployment considerations.
3.2.4 Cluster structure visualization
[Figure 2] presents t-SNE visualizations of the learned quantum feature spaces for EQC and selected baselines on NSL-KDD. These visualizations are provided for qualitative illustration only — no quantitative claims rest on them, and t-SNE projections can be misleading if over-interpreted (all quantitative conclusions derive from [Table 1] through [Table 3]). With that caveat stated, the visualizations do show more distinct cluster separation for EQC than for k-means or VQC, particularly for the Probe and DoS superclasses, which appear as well-separated regions in the EQC projection but partially overlapping in the classical baselines.
[Figure 3] presents a row-normalized confusion matrix for EQC on NSL-KDD (k = 5), computed over 10 runs with 95% confidence intervals and Hungarian label alignment. Most misclassifications occur between related attack variants — DoS subtypes, for instance, are occasionally assigned to neighboring clusters rather than the correct one. This pattern aligns with security domain knowledge about attack similarity and does not represent a random failure mode.
3.3 Ablation studies
3.3.1 Contribution of individual equivariance components
[Table 4] isolates the contribution of each equivariance component — rotational symmetry, reflectional symmetry, and parameter sharing — by systematically removing each from the full EQC model and measuring the resulting change in accuracy and privacy leakage across all three datasets.
Removing rotational equivariance alone causes accuracy to drop by approximately 6.7–6.8 percentage points and privacy leakage to increase by a similar margin. Removing reflectional equivariance produces a smaller but consistent degradation of 3.4–3.8 points. The most consequential ablation is parameter sharing: removing it causes accuracy to fall by more than 10 percentage points and privacy leakage to increase by 12.5–14.2 points across datasets. Removing all equivariance constraints simultaneously reduces accuracy by 15–16 points and raises privacy leakage by 27–39 points — the full magnitude of EQC's headline improvement over unconstrained VQC [Table 4].
[Figure 4] visualizes these effects by attack type for membership inference, model inversion, and attribute inference attacks under fixed ε_tot = 1.0. Rotational equivariance appears especially protective against membership inference; reflectional equivariance matters most for attribute inference. Parameter sharing provides broad-spectrum protection across all three attack types (Cohen & Welling, 2016; Maron et al., 2018).
3.3.2 Symmetry versus parameter reduction: a capacity-matched test
This is probably the most important ablation in the paper, and the results are worth reading carefully. [Table 5] compares four variants all constrained to exactly 24 independent parameters: EQC with structured p4m sharing, a random sharing baseline with no symmetry structure, a permutation-equivariant baseline that shares parameters across semantically similar feature groups, and an unconstrained VQC with 112 parameters.
EQC achieves 79.3% accuracy (± 1.5). Random Sharing achieves 78.1% (± 1.6). The difference is not statistically significant (p = 0.12, paired t-test). Permutation Equivariance achieves 77.4% (± 1.7) — also comparable. Unconstrained VQC, with nearly five times as many parameters, achieves only 63.5% (± 2.1), significantly worse (p < 0.001). The conclusion from [Table 5] is clear, if somewhat deflating for the symmetry motivation: it is parameter reduction — regularization — that drives the privacy and utility improvements, not p4m symmetry specifically. Any structured sharing scheme of comparable parameter count performs similarly. This finding is reported honestly here, and the framework's contribution is better understood as parameter-efficient quantum clustering with differential privacy than as symmetry-specific quantum privacy preservation (Bronstein et al., 2021).
3.3.3 Effect of quantum kernel parameters on security
[Table 6] examines how circuit depth, entanglement pattern, and feature encoding scheme jointly affect clustering accuracy and a composite security score (defined as 1 − Privacy Leakage/100 + Accuracy/100). Increasing circuit depth from 2 to 4 layers produces meaningful gains in both accuracy and privacy. Beyond depth 4, improvements plateau — depth 6 yields only marginal gains over depth 5, confirming that L = 4 is the appropriate operating point. Structured entanglement aligned to p4m topology outperforms both linear and all-to-all entanglement patterns. The hybrid amplitude–angle encoding scheme consistently outperforms pure amplitude or pure angle encoding, with the full EQC configuration achieving the highest security score of 0.705 [Table 6].
3.3.4 Influence of circuit depth on formal privacy guarantees
[Table 7] reports four privacy metrics — membership inference attack success rate, attribute inference error, reconstruction error, and differential privacy ε — across circuit depths 1 through 6. Privacy improves substantially between depths 1 and 4: membership inference success falls from 58.7% to 45.3%, attribute inference error rises from 52.3% to 67.2%, and formal ε decreases from 3.25 to 1.42. Between depths 4 and 6, gains are minimal (ε moves from 1.42 to 1.32). This plateau pattern is consistent with the accuracy results and reinforces L = 4 as the optimal operating point for near-term hardware with finite coherence budgets [Table 7], [Figure 5].
3.3.5 Sensitivity to preprocessing choices
[Table 8] evaluates six preprocessing combinations across dimensionality reduction method (PCA vs. autoencoder), normalization scheme (standard vs. MinMax), and privacy mechanism (none vs. noise addition vs. noise plus quantization). The autoencoder with MinMax normalization and noise plus quantization achieves the best accuracy (79.3%) and the lowest privacy leakage (38.3%) — the full EQC configuration. PCA with standard normalization and no privacy mechanism achieves 75.3% accuracy but 52.8% privacy leakage, confirming that preprocessing choices have substantial privacy implications independent of the quantum circuit design.
[Figure 6] visualizes these preprocessing effects across attack types. The combination of autoencoder-based reduction, MinMax scaling, and noise-plus-quantization provides the most consistent privacy protection across all attack categories, with no single category showing an anomalous vulnerability.
3.4 Robustness to privacy attacks
3.4.1 Membership inference attack resistance
[Figure 7] presents membership inference attack success rates across all methods and datasets. EQC's attack success rate of 38.3% is the lowest of any method tested — 40.2 percentage points below standard k-means (78.5%), 13.8 points below DP-K-means (52.1%), and 27.1 points below VQC (65.4%). These comparisons are made under identical evaluation conditions: shadow model approach with four shadow models per target, each trained on disjoint 25% subsets, with a 2-layer MLP (64 hidden units, ReLU) as the attack classifier (Shokri et al., 2017).
[Table 9] disaggregates by attack type — shadow model, threshold, and loss-based attacks — and reports a composite resistance score (where 1.0 would represent perfect resistance and 0.0 would represent complete vulnerability). EQC achieves a resistance score of 0.617, compared to 0.495 for DiffP-Spectral, 0.479 for DP-K-means, and 0.346 for VQC. The protection stems from three interacting mechanisms: differential privacy noise limits what the kernel matrix reveals about individual records; parameter sharing prevents the circuit from memorizing specific data presentations; and the inherent lossy nature of quantum measurement means that even access to the kernel does not reconstruct the underlying states (Yeom et al., 2018; Schuld & Killoran, 2019).
3.4.2 Model inversion attack resistance
Model inversion attacks attempt to reconstruct input records from clustering outputs — a particularly serious risk in healthcare applications where even partial reconstruction of patient features can constitute a privacy breach. [Figure 8] and [Table 10] report reconstruction error (MSE) across gradient-based and optimization-based reconstruction methods.
EQC's average reconstruction error is 0.568, compared to 0.235 for standard k-means (baseline), 0.387 for DP-K-means, and 0.325 for VQC. Expressed as a privacy protection factor relative to k-means, EQC achieves 2.42 — meaning reconstruction from EQC outputs is approximately 2.4 times harder than from unprotected k-means outputs. No other method exceeds a factor of 1.65 [Table 10]. It is worth being candid about the interpretation here: in the classical simulation setting, the no-cloning theorem and measurement collapse — which would provide genuine protection on real quantum hardware — are not operative. The reconstruction resistance observed here comes from the combined effect of DP noise, parameter reduction, and the lossy quantum-inspired encoding process (Lloyd et al., 2013).
3.4.3 Attribute inference attack resistance
[Figure 9] and [Table 11] report attribute inference error across demographic, behavioral, and sensitive attribute categories. EQC achieves an average attribute inference error of 72.5%, compared to 32.7% for k-means, 60.8% for DiffP-Spectral, and 45.7% for VQC. Protection is strongest for behavioral attributes (74.2% error), which is significant given that behavioral data — user activity logs, session patterns, clinical trajectories — represents some of the most sensitive content in the target application domains (Yeom et al., 2018; Maron et al., 2018).
3.5 Noise resilience
3.5.1 Robustness under Gaussian and structured noise
[Figure 10] plots clustering accuracy as a function of Gaussian noise standard deviation (σ ∈ [0, 0.5]) for EQC and selected baselines on NSL-KDD. EQC maintains above 70% accuracy up to σ = 0.2 and above 60% up to σ = 0.3, degrading more gradually than any baseline method. Privacy leakage remains below 40% throughout this range, which means the privacy-utility balance is preserved even under moderately adversarial noise conditions.
[Table 12] extends this to four noise types — Gaussian (σ = 0.2), salt-and-pepper (density = 0.1), Laplacian, and uniform — reporting clean accuracy, noisy accuracy, and a retention percentage (noisy accuracy as a fraction of clean accuracy). EQC retains 90.8% of clean performance on average across noise types. The next best method, VQC, retains 76.9%. Standard k-means retains only 66.2%. The equivariance constraints appear to play a genuine regularizing role here, making the circuit's behavior more stable across perturbations in a way that is consistent with theoretical predictions from geometric deep learning (Cohen & Welling, 2016; Bronstein et al., 2021).
3.5.2 Robustness under realistic hardware noise
The hardware noise analysis is probably the most practically important result in this paper for researchers planning near-term quantum implementations. [Table 13] reports accuracy and membership inference attack success across shot counts from 1,000 to 100,000, simulated using the IBM Quantum ibm_cairo noise model (depolarizing noise p₂ = 1.5 × 10⁻², p₁ = 5 × 10⁻⁴; readout error P(0→1) = 0.018, P(1→0) = 0.022; coherence times T₁ = 100 μs, T₂ = 80 μs).
At infinite shots (noiseless statevector simulation), EQC achieves 78.4% accuracy and 38.3% MIA success — the headline results. At 10,000 shots, a realistic near-term operating point, accuracy falls to 62.3% (± 2.8) and MIA success rises to 54.7% (± 3.1). Performance improves with shot count but plateaus around 50,000 shots due to coherent noise effects that additional sampling cannot resolve. For comparison, unconstrained VQC drops to 51.8% at 10,000 shots, suggesting that symmetry-constrained circuits do show modest noise resilience relative to unstructured alternatives — though the absolute degradation from noiseless to near-term conditions is substantial for both [Table 13].
The privacy implications of this degradation deserve explicit attention. At 10,000 shots, MIA success of 54.7% is meaningfully higher than the 38.3% achieved under noiseless simulation. It remains below the 62.2% theoretical upper bound for ε = 1.0, δ = 10⁻⁵ derived from Equation (4) — so formal differential privacy guarantees are not violated — but the practical privacy protection is noticeably weaker than the headline results suggest. Near-term deployment would require either explicit error mitigation techniques such as zero-noise extrapolation, or a hybrid architecture that offloads noise-sensitive operations to classical processors while retaining quantum computation only for components that can tolerate the noise floor (Dwork et al., 2006; Mironov, 2017).
