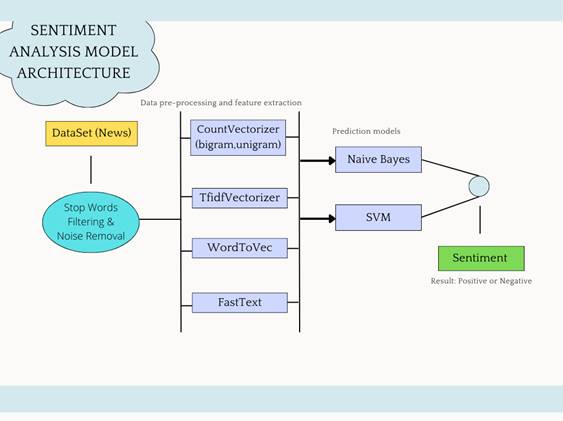
2.1 Study Design and Analytical Framework
This study was structured as a two-stage predictive modelling task rather than a single end-to-end pipeline, and that distinction shapes how the rest of this section is organised. The first stage is concerned purely with language — classifying the emotional valence of financial news text. The second stage is concerned with time — forecasting next-day stock price movement using both historical price and the sentiment signal produced in the first stage. The two stages were kept deliberately separable and independently evaluable, partly so that errors could be diagnosed at their source (a weak sentiment classifier and a weak time-series model produce very different failure signatures), and partly because this mirrors how much of the prior literature has framed the problem (Li et al., 2014; Li et al., 2020; Mohan et al., 2019). Figure 1 summarises the overall architecture; the subsections below proceed in the order data actually moved through the system — acquisition, preprocessing, feature construction, model training, and evaluation — so that, in principle, another researcher could follow the same sequence and reproduce the pipeline from raw inputs.
2.2 Data Sources and Acquisition
Sentiment training corpus. No sentiment-labelled dataset existed for the target company’s own news coverage, so a separate, independently labelled corpus was first required to train a general-purpose financial sentiment classifier. The India Financial News Headlines Sentiments dataset was retrieved from Kaggle (https://www.kaggle.com/datasets/harshrkh/india-financial-news-headlines-sentiments). This corpus was selected for two practical reasons: scale and provenance. It comprises more than 200,000 financial news headlines spanning 2017 through 2021, each pre-labelled by sentiment polarity — sufficient volume to train a supervised classifier without immediately running into the data-scarcity problems that are common in financial natural-language-processing (NLP) work, where labelled, domain-specific corpora tend to be small. Three fields were retained from the full dataset: sentiment label, headline title, and publication date. After filtering to the positive and negative classes used for binary classification, the working corpus comprised 92,383 positive headlines and 108,118 negative headlines (Figure 2) — a class distribution that, while not perfectly balanced, was close enough that no additional resampling was applied. [Authors should specify here the exact inclusion/exclusion criteria applied when filtering the raw Kaggle file — e.g., handling of duplicate headlines, non-English text, or missing dates — to allow independent reconstruction of the working corpus.]
Target-company news corpus. A sentiment classifier trained on a general corpus is only useful if it can be applied to news about the specific company being forecast, and that corpus had to be constructed separately. A custom web scraper was built to collect news headlines from a recognised financial news portal, with collection restricted to outlets carrying an established editorial track record, in order to limit the risk of incorporating fabricated or low-credibility “fake news” into the sentiment pipeline. This process yielded a corpus of more than 500 news items pertaining to the target company.
Historical stock price data. Daily historical price data for the target company were obtained from a publicly available Kaggle repository covering Apple Inc. (ticker: AAPL), spanning a seven-year period. Apple was selected as the initial test case partly for reasons of data availability and partly because a heavily traded, news-saturated stock offers a reasonably stringent test of whether sentiment signal can be extracted at all — if a signal is not detectable here, it seems unlikely to be more detectable in a thinner-coverage stock. The raw download included open, high, low, close, and volume fields; following standard practice in comparable forecasting work (Mohan et al., 2019), only the daily closing price was retained as the price-based feature for downstream modelling, since closing price is the figure most consistently used across the literature for end-of-day movement prediction and avoids the added noise introduced by intraday fluctuation.
2.3 Data Preprocessing
Text preprocessing. Before any classifier could be trained, the raw headline text needed to be normalised — an unglamorous step, admittedly, but one that disproportionately affects downstream accuracy in our experience. Two operations were applied to every headline in both the training corpus and the target-company corpus: conversion of all text to lowercase, which reduces token sparsity that would otherwise arise
Table 1. Feature Description. These four features—closing price, compound sentiment, and the positive, negative, and neutral confidence scores—constitute the input feature set for the Long Short-Term Memory (LSTM) stock prediction model described in the Methods section. Sentiment-derived features were generated by aggregating day-level outputs of the Naive Bayes and Support Vector Machine classifiers across all news items published on a given trading day.
|
Feature
|
Meaning
|
|
Price
|
The closing price of a company
|
|
Compound
|
Polarity of news sentiment
|
|
Positive
|
Confidence of positive news
|
|
Negative
|
Confidence of negative news
|
|
Neutral
|
Confidence of neutral news
|
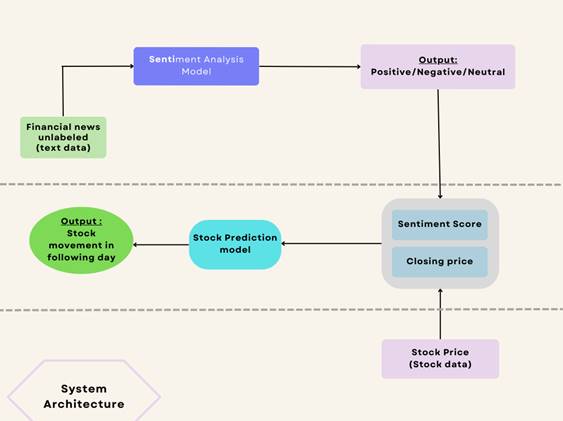
Figure 1. Architecture of the Proposed Stock Movement Prediction System. Schematic overview of the end-to-end system pipeline. Unlabeled financial news text is first passed through the sentiment analysis model, which outputs a categorical sentiment label (positive, negative, or neutral) for each news item. These outputs, together with daily closing price data obtained independently from stock market records, are combined into a unified feature set comprising sentiment score and closing price. This combined feature set is then supplied to the stock prediction model, which outputs a forecast of stock price movement for the following trading day. Dashed horizontal lines demarcate the three functional stages of the pipeline: text-based sentiment inference, feature integration, and price-movement forecasting.
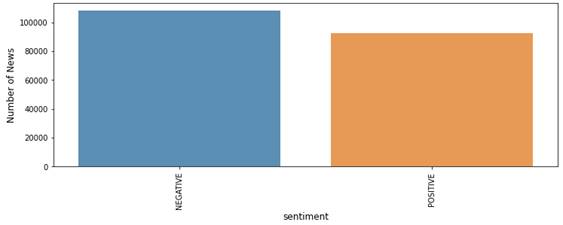
Figure 2. Class Distribution of the Sentiment-Labeled News Headline Corpus. Bar chart showing the number of headlines per sentiment class in the labeled training corpus (India Financial News Headlines Sentiments dataset; n = 200,501) used to train the sentiment classification models. The negative class comprised 108,118 headlines and the positive class comprised 92,383 headlines, reflecting a modest class imbalance that was not corrected with additional resampling prior to model training.
from inconsistent capitalisation (e.g., treating “Stock” and “stock” as distinct tokens), and removal of common English stop words, using the standard stop-word list from the Scikit-learn library (Géron, 2022), which allows the classifier to concentrate its discriminative capacity on lexically meaningful terms rather than high-frequency function words carrying little sentiment information.
Feature engineering for stock prediction. Following sentiment classification, each headline in the target-company corpus was assigned a predicted sentiment label, and these labels were aggregated to the daily level: for every trading day, the number of positive, neutral, and negative news items published was counted. This daily aggregation step was necessary because the price-prediction model operates on a daily time step, while raw news data arrives at an irregular, sub-daily frequency; aggregating counts per day is what allowed the two data streams to be aligned into a single, coherent feature table. The resulting integrated dataset comprised four features per trading day (Table 1): closing price, compound sentiment polarity, and confidence scores for positive, negative, and neutral classifications.
2.4 Feature Extraction for Text Representation
Raw text cannot be supplied directly to a machine-learning classifier, so a numerical representation step was required to bridge unstructured language and the vector-based input that supervised models expect. Three families of text-vectorisation approach were considered. Term frequency–inverse document frequency (TF-IDF) weighting was used as one candidate representation; this statistic captures how important a given word is to a document, on the intuition that a term’s weight should rise with its frequency within a document but be discounted if it appears ubiquitously across the corpus (Su et al., 2011). The CountVectorizer implementation from Scikit-learn (Géron, 2022) was also used, converting text into a numerical vector based on simple token-frequency counts and providing a straightforward bag-of-words baseline against which the TF-IDF representation could be compared. Embedding-based approaches — specifically Word2Vec and FastText — were considered as well; both pursue dense vector representations of words, but FastText extends Word2Vec by incorporating subword (n-gram) information, which lengthens training time owing to the larger number of n-gram units relative to whole words, but in exchange handles rare or out-of-vocabulary terms more gracefully — a property particularly relevant to financial headline text, where novel company names, ticker symbols, and industry-specific terminology routinely fall outside a fixed vocabulary.
2.5 Sentiment Classification Models
Two supervised classifiers — Naive Bayes and Support Vector Machine — were trained following vectorisation, selected because both have demonstrated reasonable performance on short-text sentiment-classification tasks in prior financial NLP work (Pavitha et al., 2022), while remaining computationally lightweight relative to transformer-based alternatives. Figure 3 presents the architecture of this component.
The Multinomial Naive Bayes variant was implemented, this being the form most commonly applied in NLP tasks; it rests on Bayes’ theorem, which estimates the probability of an event conditional on prior knowledge and evidence:
P(A|B) = [P(A) × P(B|A)] / P(B)
where P(A) denotes the prior probability of class A, P(A|B) denotes the posterior probability of class A given evidence B, and P(B|A) denotes the likelihood of observing evidence B given class A. The Multinomial variant operates on term frequencies — counts of how often a given word occurs within a document — normalised by document length and used to compute maximum-likelihood estimates of the conditional probabilities from the training data (Su et al., 2011).
A Support Vector Machine (SVM) classifier was also implemented, one of the most widely adopted supervised algorithms for textual polarity detection. SVM performs classification by seeking the hyperplane that optimally separates classes once the data are projected into an n-dimensional feature space; where the data are not linearly separable in their original space, kernel functions (linear, sigmoid, radial basis function, polynomial, or other non-linear variants) can be used to transform the feature space to permit separation. A linear kernel was used here, on the grounds that text-classification tasks typically involve a very high-dimensional feature space (each distinct word or token effectively constitutes its own feature), and linearly separable structure tends to emerge naturally at that dimensionality; a linear kernel also trains substantially faster than non-linear alternatives and tends to perform well whenever a reasonably clear margin separates the classes.
2.6 Stock Price Movement Prediction Model
Rationale for model selection. A Long Short-Term Memory (LSTM) recurrent neural network architecture was selected for the price-forecasting component. LSTM networks have become a common choice for stock-market prediction tasks because of their explicit design for capturing long-range temporal dependencies in sequential data (Li et al., 2020) — a property directly relevant here, since closing-price data is itself a time series, and simpler feedforward or shallow-memory architectures tend to lose access to longer-horizon patterns that may carry predictive value.
Data partitioning. The combined dataset — closing price plus daily-aggregated sentiment features — was partitioned chronologically into a training set comprising the first 80% of observations and a held-out test set comprising the remaining 20%. A random train/test split was deliberately avoided, since shuffling time-series data would allow the model to be evaluated on dates that precede some of its own training examples, producing an artificially optimistic and practically meaningless estimate of forecasting performance. The chronological split instead ensures that the test set strictly represents future time periods relative to training, which is the only evaluation configuration that meaningfully approximates real-world deployment.
Input normalisation and windowing. Prior to training, all input features were normalised to the [0, 1] interval. This step matters for two reasons: it prevents features with larger raw numeric ranges — closing price, which can run into the hundreds of dollars — from dominating the learning process relative to smaller-scale sentiment confidence scores, and it generally improves the numerical stability and convergence behaviour of gradient-based optimisation. Because LSTM networks operate on sequences rather than single time points, fixed-length input windows were constructed from the normalised time series, where each window comprises a contiguous span of historical daily observations and the associated target is the subsequent day’s stock movement. A window length of 14 trading days (roughly three calendar weeks) was used; this reflects a practical compromise, since a window too short risks omitting genuinely predictive longer-term patterns, while a window too long increases the model’s parameter burden relative to the size of the available training data. This parameter was not exhaustively tuned and represents an area for refinement in future work.
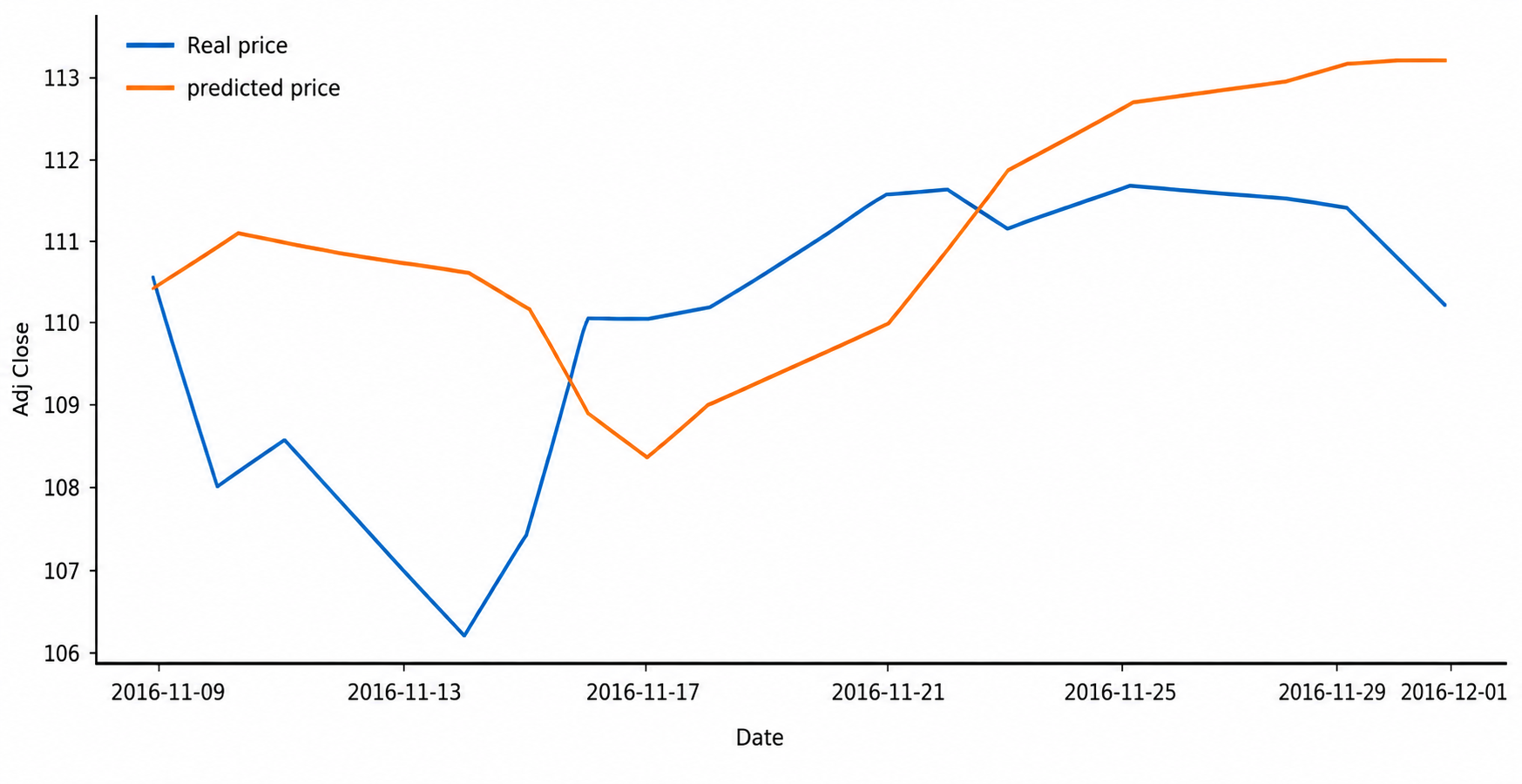
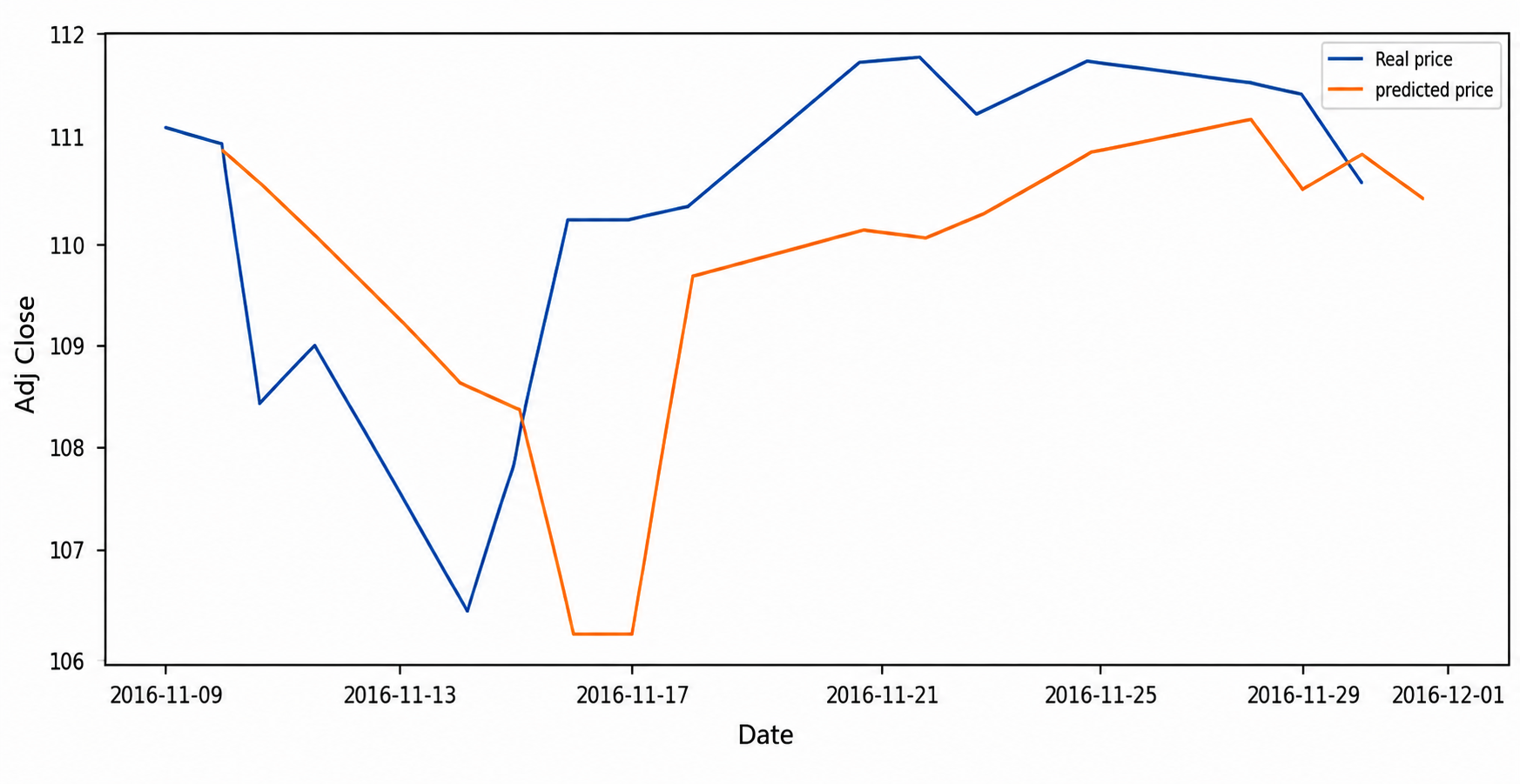
Model architecture and training procedure. The LSTM network was trained on the windowed training data, learning to map each 14-day input sequence to its corresponding target value. Model parameters were updated iteratively via gradient-based optimisation to minimise prediction error between model output and true target, using mean squared error as the loss function and the Adam optimiser for parameter updates — a pairing that is fairly standard for regression-style sequence-prediction tasks of this kind, owing to Adam’s adaptive learning-rate behaviour, which tends to produce more stable convergence than plain stochastic gradient descent, particularly when feature scales or gradient magnitudes vary across training. Two variants of this model were trained and compared: one using only the normalised closing price as input (Figure 5), and a second incorporating both closing price and the daily-aggregated sentiment features described above (Figure 6). This comparison constituted the central manipulation of the study, isolating whatever incremental contribution sentiment information makes over price history alone.
2.7 Model Evaluation
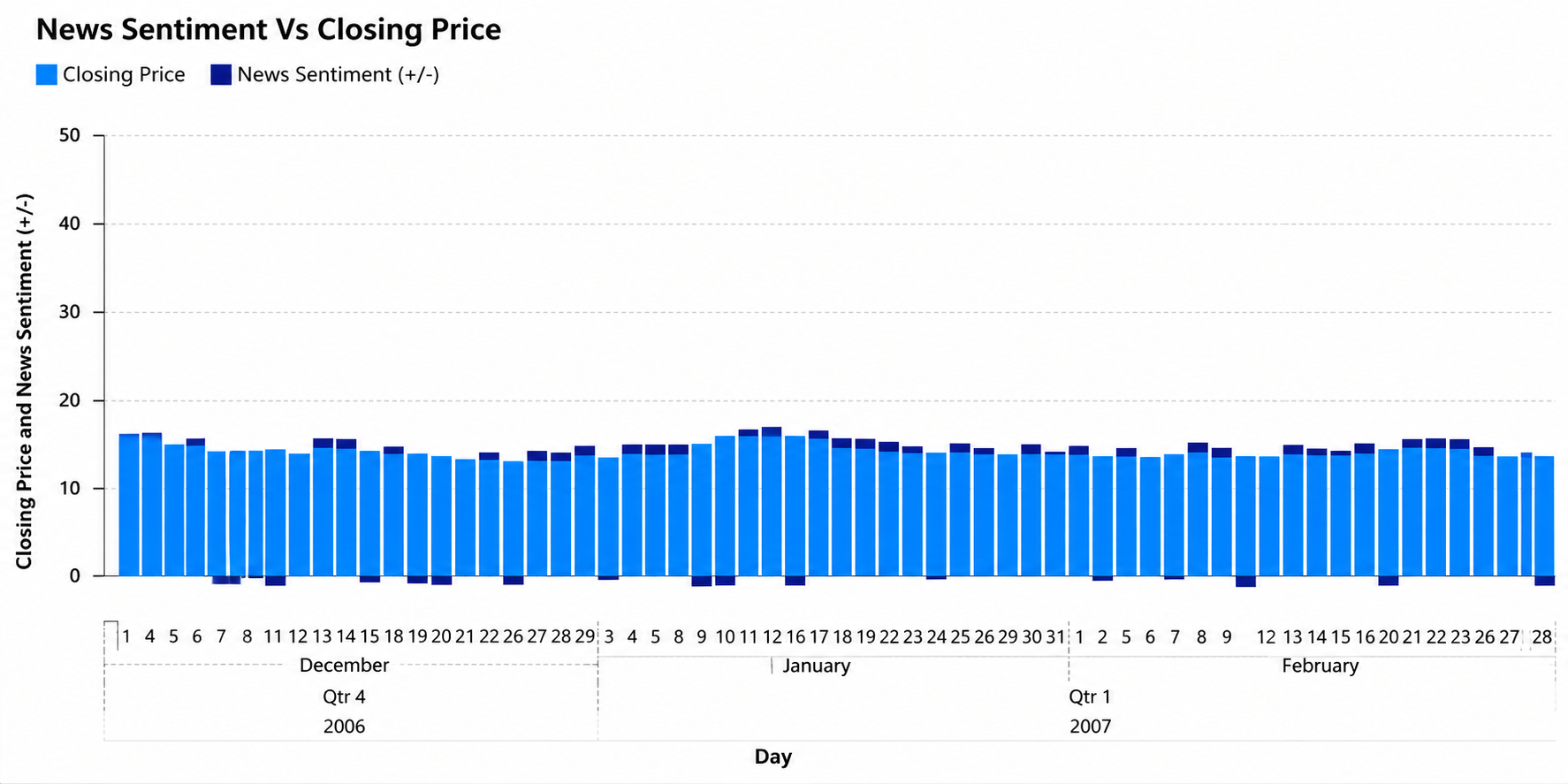
Each trained LSTM variant was applied to the held-out test set to generate predictions on previously unseen data, and predicted closing prices were compared against actual observed prices across the test period. The correlation between daily news-sentiment polarity and same-day closing-price movement (Figure 4) was additionally examined as a complementary, model-independent check on whether the underlying sentiment–price relationship the system depends on was actually present in the data, rather than relying solely on downstream forecasting accuracy to make that case indirectly. Because the sentiment classifier’s own accuracy directly bounds how much useful signal can flow into the price model, classifier-level performance (Naive Bayes and SVM accuracy) is reported separately from downstream LSTM forecasting results, so that errors attributable to language classification can be distinguished from those attributable to time-series modelling rather than being conflated into a single end-to-end metric.