1. Introduction
Text classification has become one of the foundational tasks in modern data analytics and natural language processing (NLP). At its core, the objective is relatively straightforward: to assign textual documents to predefined categories based on their semantic meaning and linguistic structure. Yet in practice the task is far from trivial. As digital communication expands at an unprecedented rate, enormous volumes of unstructured text—from online news portals, social media platforms, blogs, policy documents, and open data repositories—are produced every day. Extracting meaningful insights from such data requires automated systems capable of accurately organizing and interpreting textual information. Consequently, text classification has become an essential mechanism for enabling information retrieval, sentiment analysis, spam detection, topic labeling, and large-scale content filtering (LeCun et al., 2015; Shah et al., 2020).
Early approaches to text classification largely relied on traditional machine learning algorithms combined with handcrafted feature extraction techniques. Methods such as logistic regression, naive Bayes classifiers, decision trees, and support vector machines (SVMs) dominated the early literature because of their relative simplicity and interpretability. When paired with techniques like bag-of-words or term frequency–inverse document frequency (TF-IDF) representations, these algorithms were able to achieve reasonable performance across many classification tasks. However, as textual datasets have grown both in scale and complexity, the limitations of these approaches have become increasingly evident. Traditional methods often struggle to capture deep semantic relationships and contextual dependencies within language, which are critical for understanding the meaning of sentences or documents (Kim, 2014).
The rapid advancement of deep learning has significantly reshaped the landscape of text classification research. Neural network architectures—particularly convolutional neural networks (CNNs), recurrent neural networks (RNNs), and their variants—have demonstrated remarkable success in modeling complex linguistic patterns. CNN-based models are especially effective in extracting local features and n-gram patterns from textual sequences, while recurrent architectures such as long short-term memory networks (LSTMs) are designed to capture sequential dependencies across longer text spans. These architectures allow models to learn hierarchical and contextual representations of language automatically, reducing the need for manual feature engineering (LeCun et al., 2015; Lai et al., 2015). As a result, deep learning–based systems have become the dominant paradigm for modern NLP applications.
Despite these technological advancements, one persistent challenge continues to undermine the effectiveness of many classification models: the problem of class imbalance. Class imbalance occurs when the distribution of categories within a dataset is highly skewed, with some classes appearing far more frequently than others. In such situations, machine learning models tend to favor the majority class during training because it dominates the learning process. As a consequence, the model may achieve high overall accuracy while performing poorly on minority classes, which are often the categories of greatest interest (Kim & Kim, 2018).
The issue becomes even more consequential in domains where minority classes carry critical informational value. For example, in healthcare analytics, rare disease mentions or unusual clinical conditions may appear only infrequently within datasets but are vital for accurate diagnosis and treatment planning. Similarly, in financial systems, rare fraud cases or anomalous transactions represent a small fraction of the data yet demand precise detection. Within the context of news classification, topics related to minority rights, policy concerns, or emerging global issues may occur less frequently but remain socially and politically significant. If classification models systematically misclassify such categories, the resulting analytical insights may be incomplete or biased (Letouzé, 2012).
The consequences of class imbalance extend beyond simple misclassification errors. Research has shown that imbalanced datasets can distort model learning processes, leading to biased decision boundaries and poor generalization performance. In many cases, classifiers trained on imbalanced data exhibit high precision for majority classes but extremely low recall for minority classes. This imbalance in predictive performance ultimately reduces the reliability and fairness of automated decision systems (Thölke et al., 2023). As datasets continue to grow in size and diversity, addressing this imbalance becomes increasingly important for ensuring that machine learning models remain both accurate and equitable.
To mitigate the challenges posed by imbalanced data, researchers have proposed several strategies that broadly fall into two categories: data-level approaches and algorithm-level approaches. Data-level techniques aim to rebalance the dataset prior to model training by either oversampling minority instances or undersampling majority instances. Methods such as random oversampling, synthetic minority oversampling techniques (SMOTE), and TomekLinks have been widely explored to improve minority class representation (Hasib et al., 2020). Algorithm-level strategies, in contrast, attempt to modify the learning process itself. These include cost-sensitive learning, ensemble models, and classifier threshold adjustments designed to penalize errors in minority classes more heavily (Yin et al., 2020).
While these methods have shown promising results in many classification tasks, their effectiveness can be limited when dealing with complex textual data. Language inherently contains contextual and sequential relationships that are difficult to capture using conventional machine learning frameworks. Even with resampling strategies applied, models may still fail to recognize nuanced semantic patterns within sentences or documents. Consequently, researchers have increasingly turned to deep neural architectures that integrate contextual embeddings and sequential modeling capabilities to address both the semantic complexity of text and the structural challenges posed by imbalanced datasets (Ger et al., 2023).
Recent developments in contextual language models, particularly transformer-based architectures such as Bidirectional Encoder Representations from Transformers (BERT), have further advanced the state of the art in text representation. Unlike traditional word embeddings, contextual embeddings capture the meaning of words relative to their surrounding context, enabling more accurate semantic interpretation. Integrating these embeddings into neural classification architectures has proven highly effective in improving performance across a wide range of NLP tasks.
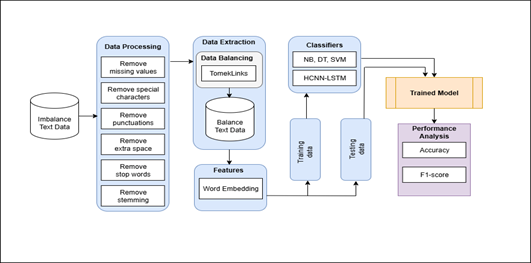
Motivated by these developments, this study proposes a hybrid deep learning architecture—referred to as the HCNN-LSTM model—to improve classification performance on imbalanced textual datasets. The proposed model combines the feature extraction strengths of convolutional neural networks with the sequential learning capabilities of LSTM networks. CNN layers are used to capture local semantic features from textual inputs, while LSTM layers model long-range contextual dependencies across sequences. To enhance semantic representation further, contextual embeddings generated by BERT are incorporated into the model pipeline. Additionally, TomekLinks undersampling is applied at the data preprocessing stage to reduce majority-class dominance and improve minority-class representation.
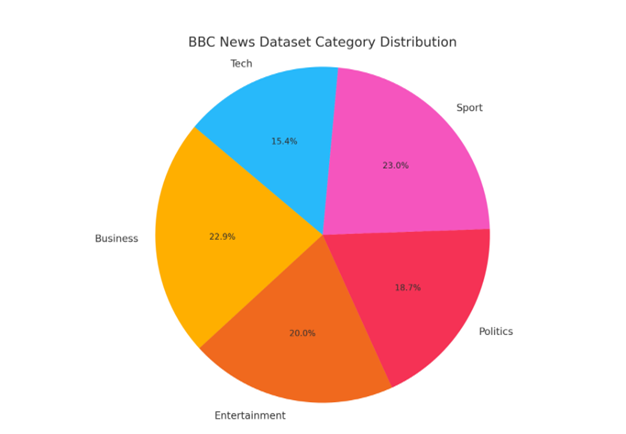
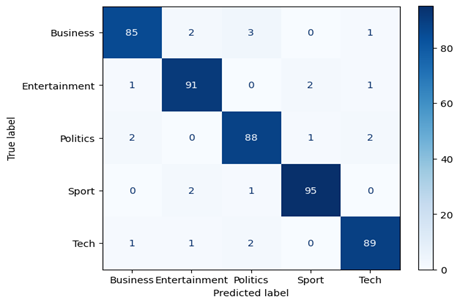
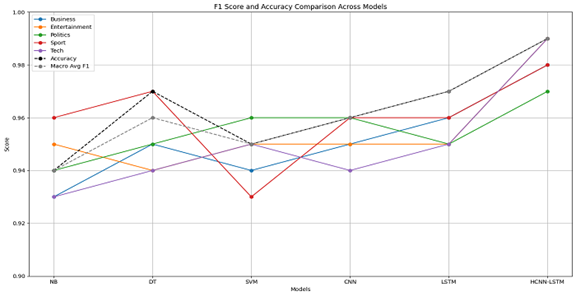
The effectiveness of the proposed HCNN-LSTM framework is evaluated using the widely recognized BBC News dataset, a benchmark corpus frequently used for text classification research. Experimental results demonstrate that the proposed hybrid architecture achieves strong classification performance and outperforms several traditional machine learning algorithms in handling imbalanced text data. These findings suggest that combining contextual embeddings with hybrid neural architectures can significantly improve classification accuracy while maintaining robustness in imbalanced environments.
The remainder of this paper is structured as follows. Section 2 reviews existing literature related to text classification and imbalanced learning approaches. Section 3 describes the proposed methodology, including data preprocessing procedures and the HCNN-LSTM model architecture. Section 4 presents the experimental design, evaluation metrics, and comparative results. Finally, Section 5 summarizes the key findings and outlines potential directions for future research. Several previous studies have investigated techniques for handling imbalanced text classification problems using machine learning and deep learning approaches. A summary of representative survey papers and their primary contributions is presented in Table 1.