1. Introduction
Healthcare, like most of modern life, has gone digital — and not gradually, either. Over the past decade, the Electronic Health Record has shifted from a convenience to something closer to infrastructure: a single repository where a patient's history, labs, medications, and clinical notes converge (Menachemi & Collum, 2011). That convergence was supposed to make care easier to coordinate, and in many ways it has. But it has also done something its early architects probably didn't fully anticipate — it created an enormous, continuously growing dataset that artificial intelligence is now well positioned to exploit, for better or for worse (Alowais et al., 2023).
Clinical Decision Support Systems, or CDSS, sit at the center of that opportunity. At their simplest, they are tools meant to nudge clinicians toward better decisions — flagging a drug interaction, estimating a risk score, suggesting a next step (Sutton et al., 2020). The earliest versions of these systems were rule-based, built on if-this-then-that logic distilled from clinical guidelines. That approach is transparent, which is its strength, but also rigid, which is its weakness; it tends to buckle under the sheer variability of real patient data (Berge et al., 2023). AI-driven CDSS, by contrast, can learn patterns from EHR data that no fixed rule set would ever capture — though, as is often the case with machine learning, that flexibility comes at a cost.
The cost is interpretability. Many of the models capable of finding those subtle patterns — deep neural networks especially — arrive at conclusions through pathways that are, frankly, difficult even for their own developers to fully unpack (Rajkomar et al., 2018). For a retailer recommending products, that opacity is a minor inconvenience. For a clinician deciding how to treat a patient, it's something closer to a dealbreaker. Trust, accountability, and regulatory approval all tend to hinge on being able to explain why a model said what it said (Amirahmadi et al., 2023; Poongodi et al., 2021).
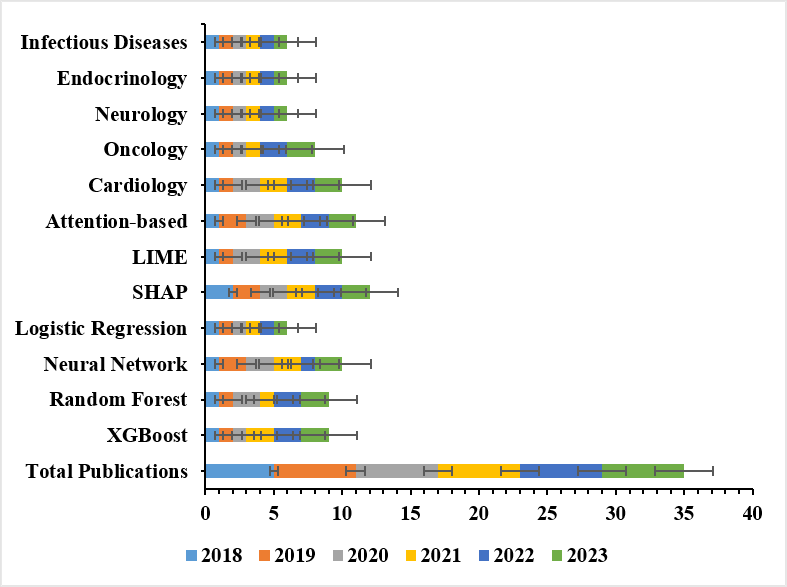
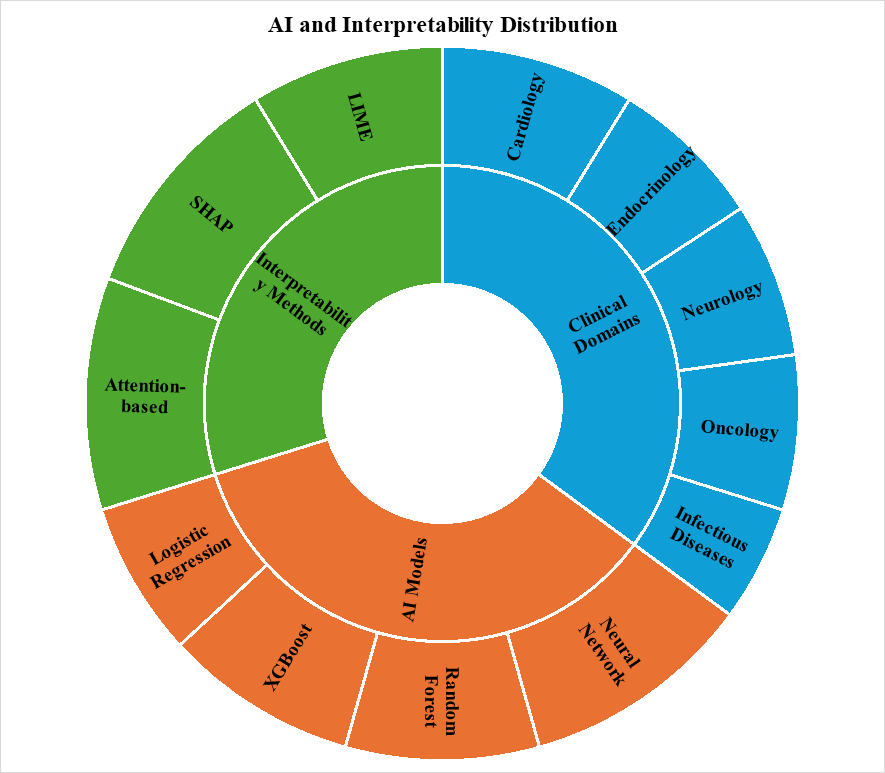
This is where interpretable AI — sometimes called explainable AI, or XAI — enters the picture. The core idea isn't new in spirit (clinicians have always wanted explanations), but the tools are: SHAP (Shapley Additive Explanations), LIME (Local Interpretable Model-agnostic Explanations), and attention-based visualization each offer a different lens onto a model's reasoning, translating statistical weight into something resembling clinical logic (Combi et al., 2022; Linardatos et al., 2020). And there's at least preliminary evidence that this matters in practice — that clinicians are more willing to act on, and integrate, recommendations they can actually see the reasoning behind, rather than ones delivered as an unexplained verdict (Lauffenburger et al., 2023).
Where this has taken hold first is telling. Cardiology, oncology, and a handful of other data-rich specialties have led the way, likely because their EHR data tend to be well-structured and their outcomes relatively easy to define (Srinivasu et al., 2022). Infectious disease modeling, meanwhile, has been gaining ground of its own — partly, one suspects, a downstream effect of recent years' renewed interest in epidemic forecasting. And the geography of this research is broadening too: substantial contributions are now coming not just from the usual high-income settings but from a wider, more international set of health systems (Antoniadi et al., 2021).
None of which is to say the field has solved its problems. Far from it. EHR data quality varies enormously across institutions, interoperability remains patchy, and a model trained on one hospital's patient population may simply not generalize to another's (Srinivasu et al., 2022). There's also a softer, more human challenge lurking underneath the technical ones — interpretability outputs are only useful if clinicians can actually read them without being overwhelmed, which means interface design, training, and cognitive load all deserve more attention than they typically receive (Wysocki et al., 2023).
Given all this, the present review had a fairly specific aim: to map, systematically, how interpretable AI has actually been applied within EHR-based CDSS — which models, which interpretability techniques, which clinical domains, and where, geographically, the research has concentrated. The goal is less to settle the question than to lay out, clearly, where the evidence currently stands, so that the next wave of research — and implementation — has somewhere solid to start from (Tufael et al., 2023).