1. Introduction
There is something quietly remarkable about the pace at which artificial intelligence has moved from the research margins into the heart of clinical medicine. Less than a decade ago, the notion of an algorithm reviewing an electrocardiogram or flagging early-stage sepsis from electronic health record data would have struck most clinicians as ambitious speculation. Today, such systems exist — and in some contexts, they perform with accuracy that rivals or exceeds human specialists (Rajpurkar et al., 2022). This is not a trivial development. Healthcare systems worldwide are strained: aging populations, physician shortages, diagnostic backlogs, and the crushing informational burden of modern medicine all create pressure for tools that can help clinicians think faster, more consistently, and with greater breadth (Topol, 2019). Clinical Decision Support Systems (CDSS) have long been positioned as one answer to that pressure.
But here is where the story gets complicated. The majority of high-performing AI models in healthcare are deep neural networks — architectures that achieve their accuracy, at least in part, through complexity that resists human interpretation. A physician reviewing an AI recommendation cannot, in most cases, trace the logic backward to its origins. Why did the model flag this patient for cardiac risk? What features drove that recommendation? Without answers to these questions, the clinical encounter between a doctor, a patient, and an AI system has an uncomfortable asymmetry: the machine knows something it cannot explain, and the clinician must decide whether to trust it. Unsurprisingly, this opacity has been identified as one of the primary barriers to AI adoption in clinical settings (Adadi & Berrada, 2018; Hulsen, 2023).
Equally troubling — perhaps more so — is the question of where patient data goes when AI learns from it. Traditional machine learning pipelines in healthcare require centralizing data: pulling records from hospitals, clinics, and diagnostic laboratories into a shared repository where the model trains. This architecture is expedient, but it creates significant exposure. Centralized repositories are attractive targets for cyberattacks. They create regulatory complexity under frameworks such as HIPAA and GDPR. And they demand that patients and institutions surrender a form of data sovereignty that many are, justifiably, reluctant to yield (Saraswat et al., 2022). Several high-profile breaches of healthcare databases in recent years have made this not a theoretical concern but a lived reality for millions of patients (Nazar et al., 2021).
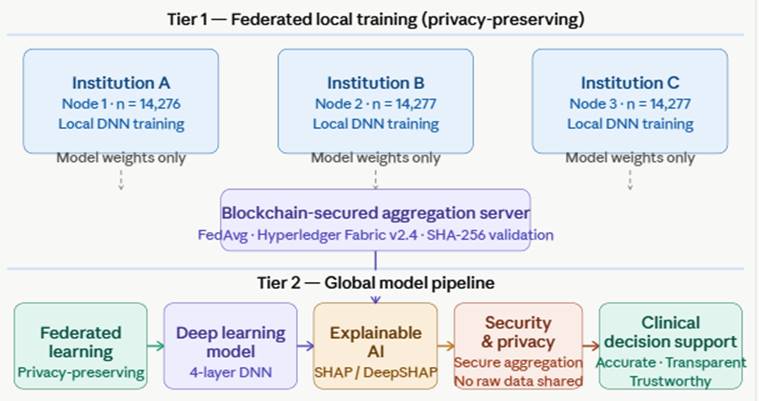
Federated learning, proposed by McMahan et al. (2017) as a general framework for decentralized model training, offers a conceptually elegant solution to the data privacy problem. Rather than aggregating raw patient records, federated learning keeps data local — within each institution's secure environment — and instead shares only model updates (gradients or weights) with a central aggregation server. The global model improves through collaboration without any institution ever exposing its underlying data. This architecture has been applied in healthcare contexts with considerable promise, demonstrating that multi-institutional collaboration is achievable without the privacy costs of data pooling (Rieke et al., 2020).
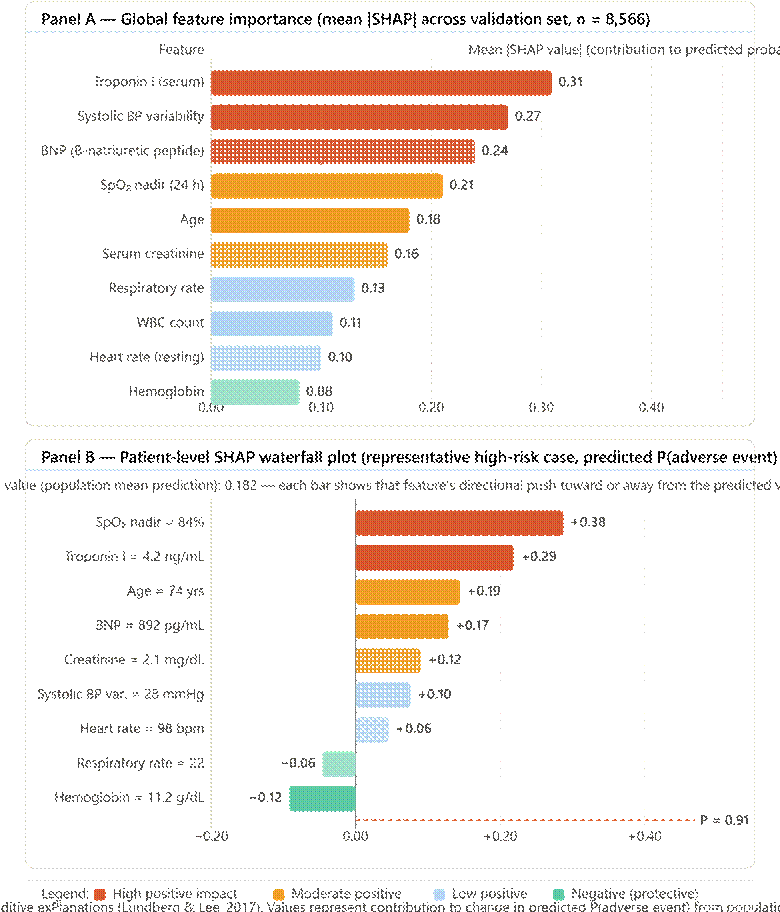
Yet federated learning alone does not solve the transparency problem. A federated model can be just as opaque as a centralized one. And transparency alone — achieved through techniques like SHAP (SHapley Additive exPlanations; Lundberg & Lee, 2017) or LIME (Ribeiro et al., 2016) — does not ensure that the underlying training process is secure against adversarial manipulation, gradient inversion attacks, or model poisoning. What the field has needed, and what the literature has so far addressed only in fragments, is a unified framework that handles all three challenges simultaneously: privacy through federated learning, transparency through explainable AI, and security through cryptographic and distributed consensus mechanisms (Allana et al., 2025; Kim et al., 2024).
This paper presents the Federated Explainable AI (FEXAI) Framework — an integrated architecture designed to meet exactly those requirements. The framework combines TensorFlow Federated (TFF) for distributed model training, SHAP for post-hoc feature attribution and clinical interpretability, and a blockchain-anchored aggregation protocol to ensure the integrity of model updates across institutions. To our knowledge, this is among the first architectures to integrate these three components into a single deployable system evaluated against benchmark clinical datasets. The research is motivated not by the ambition of novelty for its own sake, but by a practical question: can we build clinical AI that is, simultaneously, accurate enough to be useful, transparent enough to be trusted, and secure enough to be deployed?
The remainder of this paper is organized as follows. Section 2 reviews the relevant literature on CDSS, federated learning, and explainable AI. Section 3 describes the methodology, dataset, and experimental setup in full reproducible detail. Section 4 presents quantitative results alongside illustrative SHAP analyses. Section 5 interprets the findings and their clinical implications, and Section 6 concludes with recommendations for future research.